CPU
Where I Stopped
Physical Structure
-
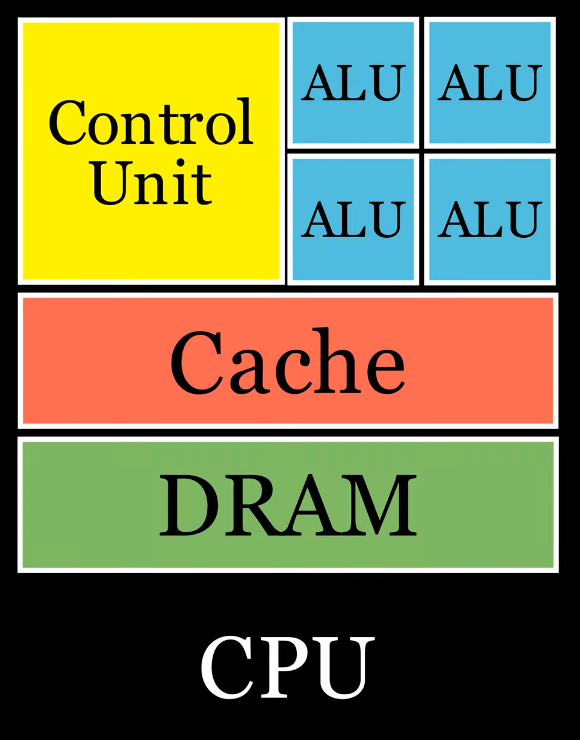 .
.
Manufacturing
-
-
Absurdly complicated, but at the same time "simple".
-
Very interesting.
-
Cache
-
Modern CPUs fetch memory in 64-byte cache lines and prefetch adjacent memory.
Performance: Fixed Array (Small Array) vs Dynamic Array
Discussion
-
Considering the struct
IK_Chain:IK_Chain :: struct { joints: [dynamic]^Joint, bone_lengths: [dynamic]f32, target: eng.Transform_Node, is_target_moving: bool, placement: IK_Placement, } -
A question about performance: I'm storing
bone_lengths: [dynamic]f32as a cache inside aIK_Chain. I opted for a[dynamic]array as I don't know for sure what the length of a chain will be. Tho, now knowing about the existence of aSmall_Array, I question whether I should make this abone_length: sarray.Small_Array(SOME_REASONABLE_NUMBER, f32), for cache locality. Seems like a trade-off between memory and speed, as by using a Small_Array I will overestimate the size of this array, to be sure to fit into all major cases of aIK_ChainI would build. For context, now aIK_Chainonly has 4~5 Joints, but it could have 20+ or more, for some creatures. I update theIK_Chainevery frame, for visuals. So, using a small array with ~20 cap would be a nice trade off, instead of using a dynamic array? Oh, probably relevant, but using this for bone_lengths would also imply that I would also use this for the joints:[dynamic]^Jointin theIK_Chain; consider that the ^Joint are on the stack. -
TLDR :
-
SmallArray wins because the entire struct + bone data often fits in 1-2 cache lines
-
Location and continuity
-
Dynamic Array :
-
A
[dynamic]f32stores its metadata (pointer, length, capacity) in the struct, but the actual data is heap-allocated. -
When you do
make([dynamic]f32, 0, capacity), Odin allocates a contiguous block of memory on the heap. All elements are stored sequentially in this block: -
[elem0][elem1][elem2]... -
As long as you don't exceed this, you're going to have the values in a fixed contiguous region.
-
Indirection / Pointer chasing.
-
-
Small_Array :
-
Is embedded directly in the struct (whether the struct is on stack/heap depends on context).
-
Elements are also contiguous, but embedded within the parent struct.
-
-
Example :
-
Ex1: Array of structs :
chains: [100]IK_Chain-
Dynamic Array :
-
Only struct metadata is contiguous. Actual data is fragmented:
[Chain0] → (heap_ptr0 → bones0) → (heap_ptr1 → joints0) [Chain1] → (heap_ptr2 → bones1) → (heap_ptr3 → joints1)
-
-
Small_Array :
-
All data (struct fields + bone lengths + joints) is in one contiguous memory block.
[Chain0][bones0][joints0][Chain1][bones1][joints1]...
-
-
-
Ex2: Single struct :
-
Dynamic Array :
-
Requires at least two separate memory loads:
-
Load
IK_Chainstruct (metadata) -
Load bone data from heap pointer
-
-
-
Small_Array :
-
All data loaded in 1-2 cache lines.
-
-
-
-
They are both backing arrays fixed at point in memory and should benefit from caching.
-
"What about the
joints?" :-
The
[dynamic]^Jointcan be problematic due to double indirection (pointer to array + pointer to Joint).-
This is worse than just dynamic arrays of values.
-
-
Dynamic Array reallocation
-
Reallocations are rare if capacity is preset, but when they occur:
-
Invalidates all caches for bone data.
-
Costs CPU cycles for allocation/memcpy.
-
-
A Small_Array avoids this entirely.
Deciding between memory efficiency and performance
-
Considerations :
-
If you only need AI data in one system and skeletons in another → Cache locality benefits diminish.
-
If you allocate for 50 creatures but typically have 10-15 → 70-80% memory wasted.
-
Bad if creature size > cache line (typically 64-128B).
-
-
DO use Small_Array for :
-
Core metadata (position, health).
-
Hot components (AI state, IK chains).
-
Fixed-size subsystems.
-
-
AVOID Small_Array for :
-
The entire Creature struct.
-
Large/variable data (animations).
-
The creatures container itself.
-
SIMD
CPU ARM
NEON
-
Vector width: 128-bit registers
-
Typical lane count: 4 lanes × 32-bit (e.g., 4 ×
float32)
SVE / SVE2 (Scalable Vector Extension)
-
Vector width: Variable.
-
Register width is not fixed (128–2048 bits in 128-bit steps).
-
Code is vector-length agnostic (designed to scale across cores).
-
-
Typical lane count: 8 lanes × 32-bit (8 ×
float32)
CPU x86/x64 (Intel / AMD)
FMA3 / FMA4 (Fused multiply-add)
-
Is often used in combination with AVX/AVX2/AVX-512.
-
Platform: x86/x64 (Intel & AMD)
-
Vector width: 256-bit registers
-
Typical lane count: 8 lanes × 32-bit (8 ×
float32)
AVX-512
-
The adoption is limited (mainly HPC, data centers, or select Intel chips).
-
Includes masking, scatter/gather, and more advanced operations.
-
Platform: x86/x64 (Intel only in select CPUs, not widely available)
-
Vector width: 512-bit registers
-
Typical lane count: 16 lanes × 32-bit (16 ×
float32)
AVX / AVX2 (Advanced Vector Extensions)
-
AVX2 Added full integer support
-
Platform: x86/x64 (Intel & AMD)
-
Vector width: 256-bit registers
-
Typical lane count: 8 lanes × 32-bit (8 ×
float32)
SSE (Streaming SIMD Extensions)
-
Superseded by AVX.
-
SSE1–SSE4 progressively added instructions but retained 128-bit width.
-
Platform: x86/x64 (Intel & AMD)
-
Vector width: 128-bit registers
-
Typical lane count: 4 lanes × 32-bit (4 ×
float32)
MMX
-
Legacy, obsolete.
-
Platform: x86/x64 (Intel & AMD)
-
Vector width: 64-bit registers
-
Typical lane count: 2 lanes × 32-bit (8 ×
float32)
RISC-V (Reduced Instruction Set Computer) (Risk-Five)
-
Is an open, modular instruction set architecture (ISA) based on the RISC (Reduced Instruction Set Computer) design principles.
-
Unlike proprietary ISAs (e.g., x86 by Intel/AMD, ARM by Arm Ltd.), RISC-V is:
-
Open source — Anyone can use or implement it without licensing fees.
-
Modular — It has a minimal base instruction set, with optional extensions (e.g., floating-point, SIMD, vector).
-
RVV (RISC-V Vector Extension)
-
Similar to ARM SVE, RVV allows hardware to define vector width.
-
Not fixed to 128, 256, or 512 bits—code adapts dynamically.
-
Scalable width: Vector registers can be from 128 to 2048 bits, depending on hardware.
-
Vector-Length Agnostic (VLA):
-
Programs don’t assume a fixed vector width.
-
Code adapts to hardware at runtime — same binary works on 128-bit or 512-bit hardware.
-
GPU
-
GPUs use SIMT (Single Instruction, Multiple Thread), not SIMD per se, but functionally similar at scale.
CUDA
-
NVIDIA GPUs
-
Vector width: Scalar SIMT
-
Typical lane count: 8 lanes × 32-bit (8 ×
float32)
OpenCL
-
Cross-vendor GPU compute
-
Vector width: Variable
-
Typical lane count: 8 lanes × 32-bit (8 ×
float32)
Wavefronts / Warps
-
Used in GPU shaders
-
Vector width: 32/64 threads
-
Typical lane count: 8 lanes × 32-bit (8 ×
float32)