-
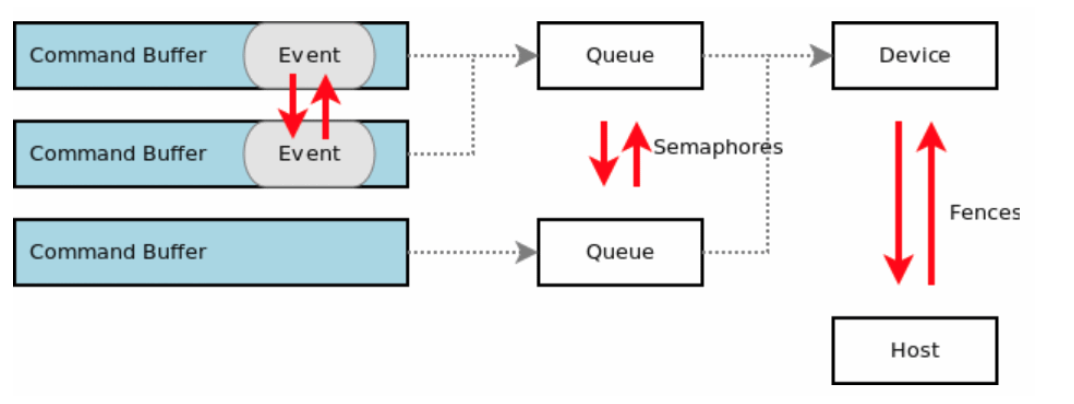 .
.
KHR_synchronization2
-
Nvidia: Use
KHR_synchronization2, the new functions allow the application to describe barriers more accurately. -
Highlights :
-
One main change with the extension is to have pipeline stages and access flags now specified together in memory barrier structures.
-
This makes the connection between the two more obvious.
-
-
Due to running out of the 32 bits for
VkAccessFlagtheVkAccessFlags2KHRtype was created with a 64-bit range. To prevent the same issue forVkPipelineStageFlags, theVkPipelineStageFlags2KHRtype was also created with a 64-bit range. -
Adds 2 new image layouts
IMAGE_LAYOUT_ATTACHMENT_OPTIMAL_KHRandIMAGE_LAYOUT_READ_ONLY_OPTIMAL_KHRto help with making layout transition easier. -
etc.
-
Queues
-
Any synchronization applies globally to a
VkQueue, there is no concept of a only-inside-this-command-buffer synchronization. -
Graphics pipelines are executable on queues supporting
QUEUE_GRAPHICS. Stages executed by graphics pipelines can only be specified in commands recorded for queues supportingQUEUE_GRAPHICS.
QueueIdle and DeviceIdle
-
These functions can be used as a very rudimentary way to perform synchronization.
-
Closing the program :
-
We should wait for the logical device to finish operations before exiting
mainLoopand destroying the window. -
You can also wait for operations in a specific command queue to be finished with
vkQueueWaitIdle. -
You’ll see that the program now exits without problems when closing the window.
-
-
Problem :
-
The problem of
vkDeviceWaitIdleorvkQueueWaitIdle, due to the lack of fences forvkQueuePresent.-
See Vulkan#Recreating , about
EXT_swapchain_maintenance1.
-
-
-
Solution :
-
Use
EXT_swapchain_maintenance1. -
See Vulkan#Recreating , for usage with swapchain.
-
-
 .
.
Queue Family Ownership Transfer
-
Resources created with a VkSharingMode of
SHARING_MODE_EXCLUSIVEmust have their ownership explicitly transferred from one queue family to another in order to access their content in a well-defined manner on a queue in a different queue family. -
Resources shared with external APIs or instances using external memory must also explicitly manage ownership transfers between local and external queues (or equivalent constructs in external APIs) regardless of the VkSharingMode specified when creating them.
-
If you need to transfer ownership to a different queue family, you need memory barriers, one in each queue to release/acquire ownership.
-
If memory dependencies are correctly expressed between uses of such a resource between two queues in different families, but no ownership transfer is defined, the contents of that resource are undefined for any read accesses performed by the second queue family.
-
A queue family ownership transfer consists of two distinct parts:
-
Release exclusive ownership from the source queue family
-
Is defined when
dstQueueFamilyIndexis one of those values.
-
Acquire exclusive ownership for the destination queue family
-
Is defined when
srcQueueFamilyIndexis one of those values.
-
Is defined if the values are not equal, and either is one of the special queue family values reserved for external memory ownership transfers
-
An application must ensure that these operations occur in the correct order by defining an execution dependency between them, e.g. using a semaphore.
-
A release operation is used to release exclusive ownership of a range of a buffer or image subresource range. A release operation is defined by executing a buffer memory barrier (for a buffer range) or an image memory barrier (for an image subresource range) using a pipeline barrier command, on a queue from the source queue family.
-
Etc, I haven't read much about it.
-
Command Buffers
-
The specification states that commands start execution in-order, but complete out-of-order. Don’t get confused by this. The fact that commands start in-order is simply convenient language to make the spec language easier to write.
-
Unless you add synchronization yourself, all commands in a queue execute out of order. Reordering may happen across command buffers and even
vkQueueSubmits. -
This makes sense, considering that Vulkan only sees a linear stream of commands once you submit, it is a pitfall to assume that splitting command buffers or submits adds some magic synchronization for you.
-
Frame buffer operations inside a render pass happen in API-order, of course. This is a special exception which the spec calls out.
Queue Submissions (vkQueueSubmit)
-
It automatically performs a domain operation from host to device for all writes performed before the command executes, so in most cases an explicit memory barrier is not needed for this case.
-
In the few circumstances where a submit does not occur between the host write and the device read access, writes can be made available by using an explicit memory barrier.
Example
-
vkCmdDispatch (PIPELINE_STAGE_COMPUTE_SHADER) -
vkCmdCopyBuffer (PIPELINE_STAGE_TRANSFER) -
vkCmdDispatch (PIPELINE_STAGE_COMPUTE_SHADER) -
vkCmdPipelineBarrier (srcStageMask = PIPELINE_STAGE_COMPUTE_SHADER) -
We would be referring to the two
vkCmdDispatchcommands, as they perform their work in the COMPUTE stage. Even if we split these 4 commands into 4 differentvkQueueSubmits, we would still consider the same commands for synchronization. -
Essentially, the work we are waiting for is all commands which have ever been submitted to the queue including any previous commands in the command buffer we’re recording.
Blocking Operations
-
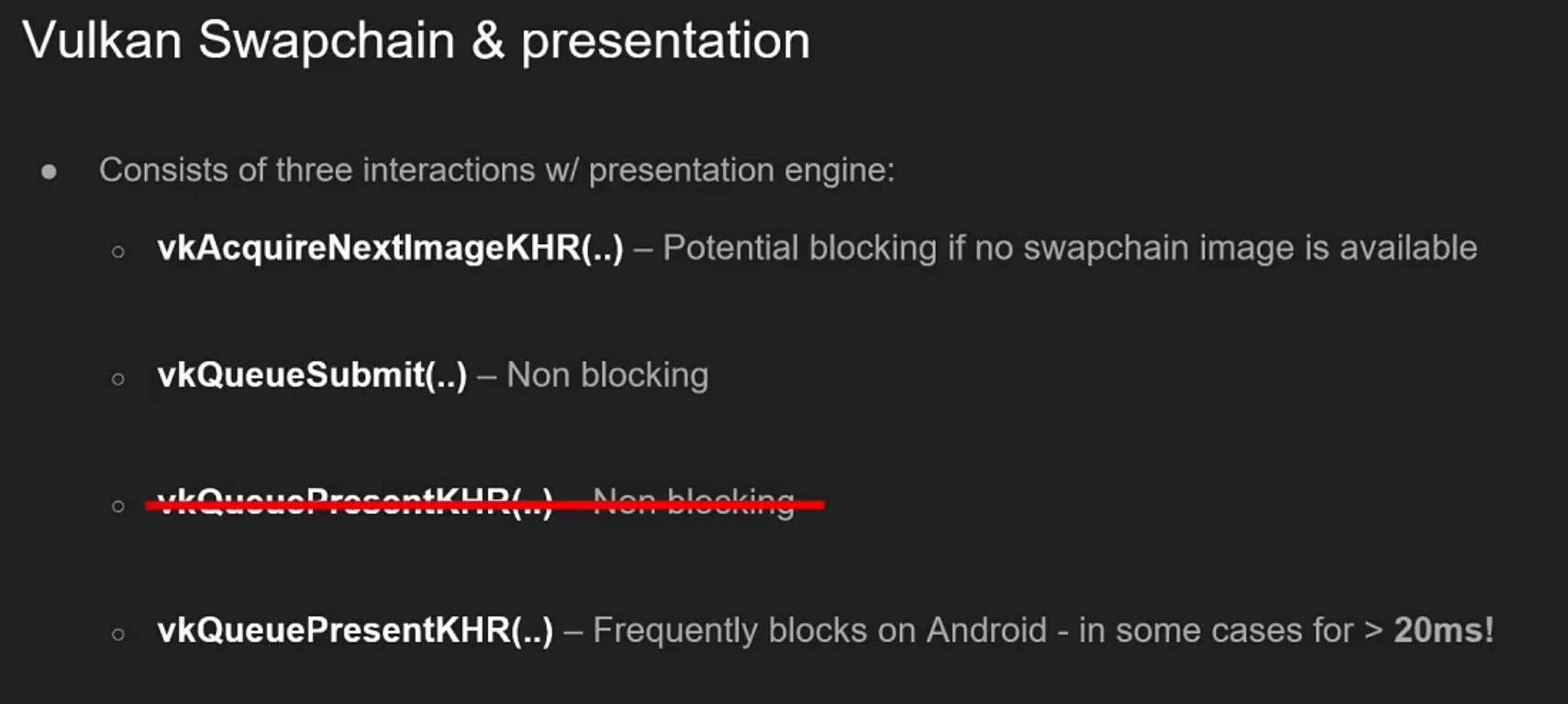 .
.
-
By Samsung 2019.
-
I don't know if this information is still valid.
-
See the Mobile section for optimizations of
vkQueuePresent.
-
Examples
-
Example 1 :
-
vkCmdDispatch– writes to an SSBO,ACCESS_SHADER_WRITE -
vkCmdPipelineBarrier(srcStageMask = COMPUTE, dstStageMask = TRANSFER, srcAccessMask = SHADER_WRITE, dstAccessMask = 0) -
vkCmdPipelineBarrier(srcStageMask = TRANSFER, dstStageMask = COMPUTE, srcAccessMask = 0, dstAccessMask = SHADER_READ) -
vkCmdDispatch– read from the same SSBO,ACCESS_SHADER_READ -
While
StageMaskcannot be 0,AccessMaskcan be 0.
-
-
Recently allocated image, to use in a compute shader as a storage image :
-
The pipeline barrier looks like:
-
oldLayout = UNDEFINED-
Input is garbage
-
-
newLayout = GENERAL-
Storage image compatible layout
-
-
srcStageMask = TOP_OF_PIPE-
Wait for nothing
-
-
srcAccessMask = 0-
This is key, there are no pending writes to flush out.
-
This is the only way to use
TOP_OF_PIPEin a memory barrier.
-
-
dstStageMask = COMPUTE-
Unblock compute after the layout transition is done
-
-
dstAccessMask = SHADER_READ | SHADER_WRITE
-
-
-
Swapchain Image Transition to PRESENT_SRC :
-
We have to transition them into
IMAGE_LAYOUT_PRESENT_SRCbefore passing the image over to the presentation engine. -
Having
dstStageMask = BOTTOM_OF_PIPEanddstAccessMask = 0is perfectly fine. We don’t care about making this memory visible to any stage beyond this point. We will use semaphores to synchronize with the presentation engine anyways. -
The pipeline barrier looks like:
-
srcStageMask = COLOR_ATTACHMENT_OUTPUT-
Assuming we rendered to swapchain in a render pass.
-
-
srcAccessMask = COLOR_ATTACHMENT_WRITE -
dstStageMask = BOTTOM_OF_PIPE-
After transitioning into this
PRESENTlayout, we’re not going to touch the image again until we reacquire the image, sodstStageMask = BOTTOM_OF_PIPEis appropriate.
-
-
dstAccessMask = 0 -
oldLayout = COLOR_ATTACHMENT_OPTIMAL -
newLayout = PRESENT_SRC_KHR
-
-
Setting
dstAccessMask = 0on the finalTRANSFER_DST → PRESENT_SRC_KHRbarrier means “there is no GPU access after this barrier that we are ordering/expressing.” For swapchain-present that is intentional and common: presentation is outside the GPU pipeline, so the barrier only needs to make the producer writes (e.g. your blitTRANSFER_WRITE) available/visible; the presentation engine performs its own, external visibility semantics.
-
-
Example 1 :
-
vkCmdPipelineBarrier(srcStageMask = FRAGMENT_SHADER, dstStageMask = ?) -
Vertex shading for future commands can begin executing early, we only need to wait once
FRAGMENT_SHADERis reached.
-
-
Example 2 :
-
vkCmdDispatch -
vkCmdDispatch -
vkCmdDispatch -
vkCmdPipelineBarrier(srcStageMask = COMPUTE, dstStageMask = COMPUTE) -
vkCmdDispatch -
vkCmdDispatch -
vkCmdDispatch
-
{5, 6, 7} must wait for {1, 2, 3}.
-
A possible execution order here could be:
-
#3
-
#2
-
#1
-
#7
-
#6
-
#5
-
-
{1, 2, 3} can execute out-of-order, and so can {5, 6, 7}, but these two sets of commands can not interleave execution.
-
In spec lingo {1, 2, 3} happens-before {5, 6, 7}.
-
-
Chain of Dependencies (1) :
-
vkCmdDispatch -
vkCmdDispatch -
vkCmdPipelineBarrier(srcStageMask = COMPUTE, dstStageMask = TRANSFER) -
vkCmdPipelineBarrier(srcStageMask = TRANSFER, dstStageMask = COMPUTE) -
vkCmdDispatch -
vkCmdDispatch
-
{5, 6} must wait for {1, 2}.
-
We created a chain of dependencies between COMPUTE -> TRANSFER -> COMPUTE.
-
When we wait for TRANSFER in 4, we must also wait for anything which is currently blocking TRANSFER.
-
-
Chain of dependencies (2) :
-
vkCmdDispatch -
vkCmdDispatch -
vkCmdPipelineBarrier(srcStageMask = COMPUTE, dstStageMask = TRANSFER) -
vkCmdMagicDummyTransferOperation -
vkCmdPipelineBarrier(srcStageMask = TRANSFER, dstStageMask = COMPUTE) -
vkCmdDispatch -
vkCmdDispatch
-
{4} must wait for {1, 2}.
-
{6, 7} must wait for {4}.
-
The chain is {1, 2} -> {4} -> {6, 7}, and if {4} is noop (no operation), {1, 2} -> {6, 7} is achieved.
-
Execution Dependencies, Memory Dependencies, Memory Model
Data hazards
-
Execution dependencies and memory dependencies are used to solve data hazards, i.e. to ensure that read and write operations occur in a well-defined order.
-
An operation is an arbitrary amount of work to be executed on the host, a device, or an external entity such as a presentation engine.
-
-
Write-after-read hazards :
-
Can be solved with just an execution dependency
-
-
Read-after-write hazards :
-
Need appropriate memory dependencies to be included between them.
-
-
Write-after-write hazards :
-
Need appropriate memory dependencies to be included between them.
-
-
If an application does not include dependencies to solve these hazards, the results and execution orders of memory accesses are undefined .
Execution Dependencies
-
An execution dependency is a guarantee that for two sets of operations, the first set must happen-before the second set. If an operation happens-before another operation, then the first operation must complete before the second operation is initiated.
-
Execution dependencies alone are not sufficient to guarantee that values resulting from writes in one set of operations can be read from another set of operations.
Memory Available
-
Availability operations cause the values generated by specified memory write accesses to become available for future access.
-
Any available value remains available until a subsequent write to the same memory location occurs (whether it is made available or not) or the memory is freed.
-
Availability operations :
-
Cause the values generated by specified memory write accesses to become available to a memory domain for future access. Any available value remains available until a subsequent write to the same memory location occurs (whether it is made available or not) or the memory is freed.
-
Even with coherent mapping, you still need to have a dependency between the host writing that memory and the GPU operation reading it.
-
-
We can say “making memory available” is all about flushing caches.
-
-
Guarantees that host writes to the memory ranges described by
pMemoryRangescan be made available to device access, via availability operations from theACCESS_HOST_WRITEaccess type. -
This is required for CPU writes, which
HOST_COHERENTeffectively provides.
-
-
Cache example :
-
When our L2 cache contains the most up-to-date data there is, we can say that memory is available , as L1 caches connected to L2 can pull in the most up-to-date data there is.
-
Once a shader stage writes to memory, the L2 cache no longer has the most up-to-date data there is, so that memory is no longer considered available .
-
If other caches try to read from L2, it will see undefined data.
-
Whatever wrote that data must make those writes available before the data can be made visible again.
-
-
Memory Domain
-
Memory domain operations :
-
Cause writes that are available to a source memory domain to become available to a destination memory domain (an example of this is making writes available to the host domain available to the device domain).
-
Memory Visible
-
Visibility operations :
-
Cause values available to a memory domain to become visible to specified memory accesses.
-
Memory barriers are visibility operations. Without them, you wouldn’t have visibility of the memory.
-
The execution barrier ensures the completion of a command, but the
srcStageMask,dstStageMask,srcAccessMaskanddstAccessMaskare what handles availability.
-
-
-
Once written values are made visible to a particular type of memory access, they can be read or written by that type of memory access.
-
We can say “making memory visible” is all about invalidating caches.
-
Availability is a necessary part of visibility, but availability alone is not sufficient.
-
You can do things that might have caused visibility, but because the write was not available, they don’t actually make the write visible.
-
-
Under the hood, visibility is implementation-specific. The pure-visibility parts typically involve forcing lines out of caches and/or invalidating them. But some kinds of visibility may not require even that.
-
vkInvalidateMappedMemoryRanges().-
Guarantees that device writes to the memory ranges described by
pMemoryRanges, which have been made available to the host memory domain using theACCESS_HOST_WRITEandACCESS_HOST_READaccess types, are made visible to the host. -
If a range of non-coherent memory is written by the host and then invalidated without first being flushed, its contents are undefined.
-
Host Coherent
-
MEMORY_PROPERTY_HOST_COHERENT-
If a memory object does have this property:
-
Writes to the memory object from the host are automatically made available to the host domain.
-
It says that you don't need
vkFlushMappedMemoryRanges()orvkInvalidateMappedMemoryRanges(). -
This property alone is insufficient for availability. You still need to use synchronization to make sure that reads and writes from CPU and GPU happen in the right order, and you need memory barriers on the GPU side to manage GPU caches (make CPU writes visible to GPU reads, and make GPU writes available to CPU reads).
-
Coherency is about "visibility", but you still need availability.
-
-
If a memory object does not have this property:
-
vkFlushMappedMemoryRanges()must be called in order to guarantee that writes to the memory object from the host are made available to the host domain, where they can be further made available to the device domain via a domain operation. -
vkInvalidateMappedMemoryRanges()must be called to guarantee that writes which are available to the host domain are made visible to host operations.
-
-
Memory Dependency
-
Memory Dependency is an execution dependency which includes availability and visibility operations such that:
-
The first set of operations happens-before the availability operation.
-
The availability operation happens-before the visibility operation.
-
The visibility operation happens-before the second set of operations.
-
-
It enforces availability and visibility of memory accesses and execution order between two sets of operations.
-
Most synchronization commands in Vulkan define a memory dependency.
-
The specific memory accesses that are made available and visible are defined by the access scopes of a memory dependency.
-
Any type of access that is in a memory dependency’s first access scope is made available .
-
Any type of access that is in a memory dependency’s second access scope has any available writes made visible to it.
-
Any type of operation that is not in a synchronization command’s access scopes will not be included in the resulting dependency.
Execution Stages
-
The Stage Masks are a bit-mask, so it’s perfectly fine to wait for both X and Y work.
-
By specifying the source and target stages, you tell the driver what operations need to finish before the transition can execute, and what must not have started yet.
-
Nvidia: Use optimal
srcStageMaskanddstStageMask. Most important cases: If the specified resources are accessed only in compute or fragment shaders, use the compute or the fragment stage bits for both masks, to make the barrier fragment-only or compute-only. -
Caio: "Wait for
srcStageMaskto finish, beforedstStageMaskcan start". -
 .
.
-
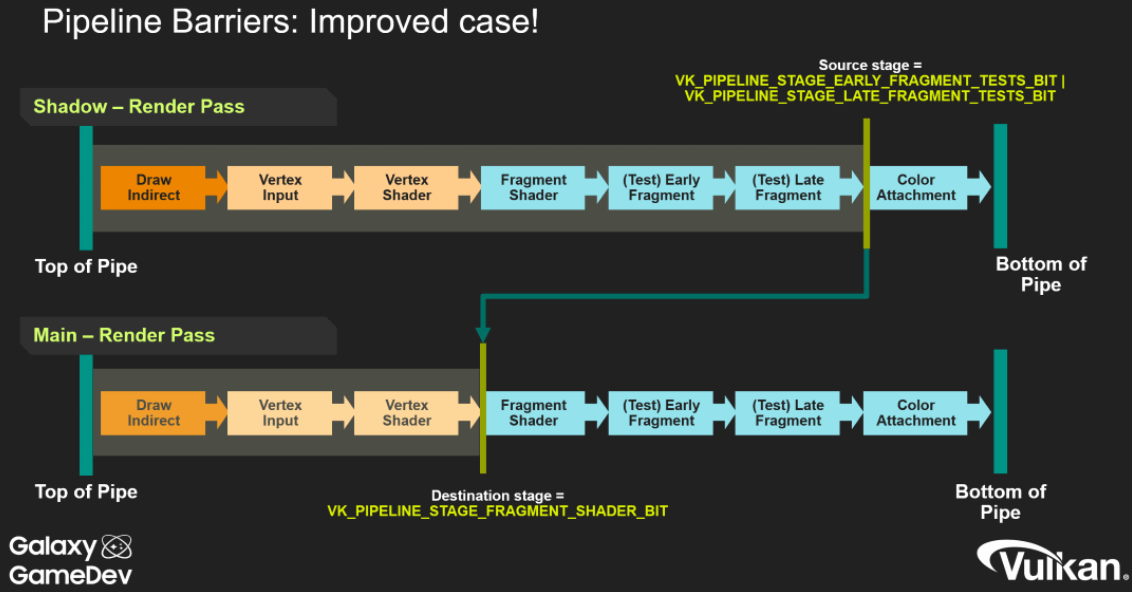 .
.
-
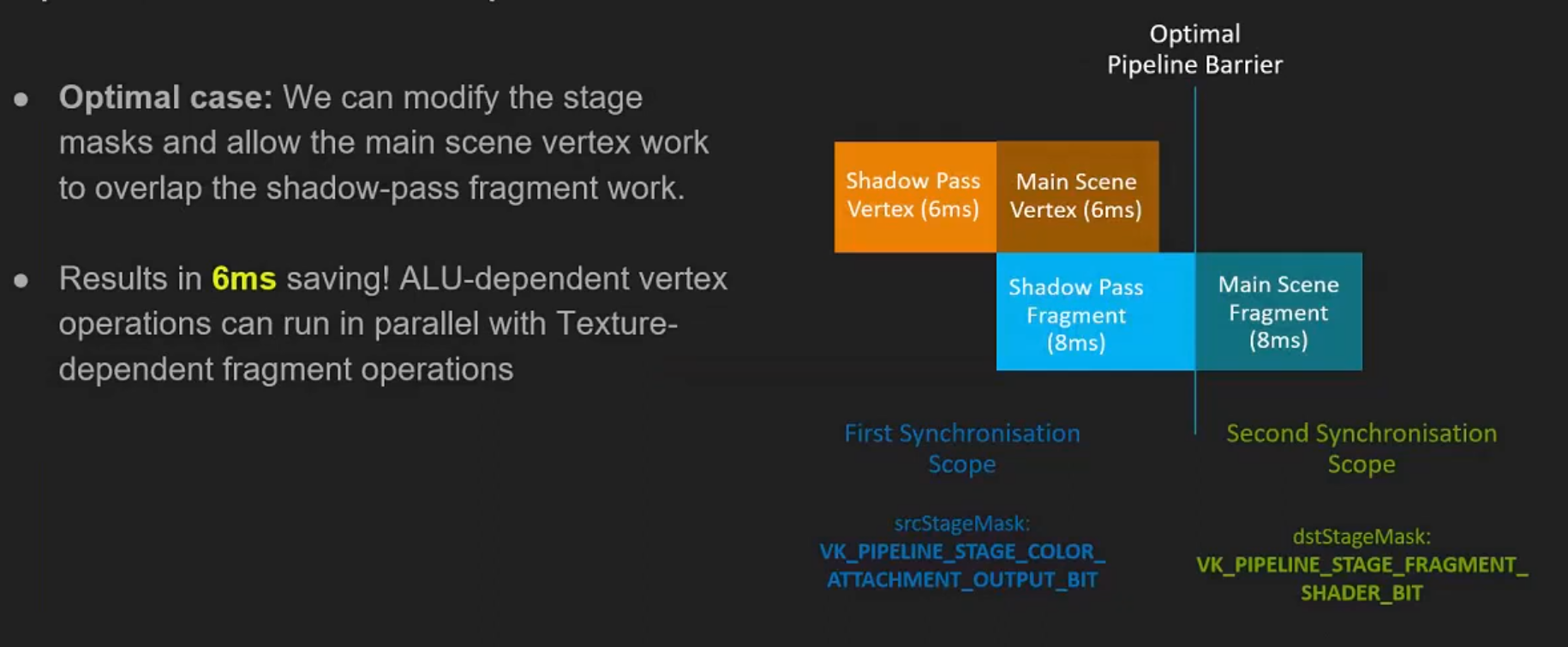 .
.
-
 .
.
First synchronization scope
-
srcStageMask -
This represents what we are waiting for.
-
"What operations need to finish before the transition can execute".
Second synchronization scope
-
dstStageMask -
"What operations must not have started yet".
-
Any work submitted after this barrier will need to wait for the work represented by
srcStageMaskbefore it can execute.
Stages
-
TOP_OF_PIPEandBOTTOM_OF_PIPE:-
These stages are essentially “helper” stages, which do no actual work, but serve some important purposes. Every command will first execute the
TOP_OF_PIPEstage. This is basically the command processor on the GPU parsing the command.BOTTOM_OF_PIPEis where commands retire after all work has been done. -
Both these pipeline stages are deprecated, and applications should prefer
ALL_COMMANDSandNONE. -
Memory Access :
-
Never use
AccessMask != 0with these stages. These stages do not perform memory accesses . AnysrcAccessMaskanddstAccessMaskcombination with either stage will be meaningless, and spec disallows this. -
TOP_OF_PIPEandBOTTOM_OF_PIPEare purely there for the sake of execution barriers, not memory barriers.
-
-
-
TOP_OF_PIPE-
In the first scope:
-
Equivalent to
NONE -
Is basically saying “wait for nothing”, or to be more precise, we’re waiting for the GPU to parse all commands.
-
We had to parse all commands before getting to the pipeline barrier command to begin with.
-
-
-
In the second scope:
-
Equivalent to
ALL_COMMANDSwithVkAccessFlags2set to0.
-
-
-
BOTTOM_OF_PIPE-
In the first scope:
-
Equivalent to
ALL_COMMANDS, withVkAccessFlags2set to0.
-
-
In the second scope:
-
Equivalent to
NONE. -
Basically translates to “block the last stage of execution in the pipeline”.
-
“No work after this barrier is going to wait for us”.
-
-
-
NONE-
Specifies no stages of execution.
-
-
ALL_COMMANDS-
Specifies all operations performed by all commands supported on the queue it is used with.
-
Basically drains the entire queue for work.
-
-
ALL_GRAPHICS-
Specifies the execution of all graphics pipeline stages.
-
It's the same as
ALL_COMMANDS, but only for render passes. -
Is equivalent to the logical OR of:
-
DRAW_INDIRECT -
COPY_INDIRECT -
TASK_SHADER -
MESH_SHADER -
VERTEX_INPUT -
VERTEX_SHADER -
TESSELLATION_CONTROL_SHADER -
TESSELLATION_EVALUATION_SHADER -
GEOMETRY_SHADER -
FRAGMENT_SHADER -
EARLY_FRAGMENT_TESTS -
LATE_FRAGMENT_TESTS -
COLOR_ATTACHMENT_OUTPUT -
CONDITIONAL_RENDERING -
TRANSFORM_FEEDBACK -
FRAGMENT_SHADING_RATE_ATTACHMENT -
FRAGMENT_DENSITY_PROCESS -
SUBPASS_SHADER -
INVOCATION_MASK -
CLUSTER_CULLING_SHADER
-
-
Order of execution stages
-
Ignoring
TOP_OF_PIPEandBOTTOM_OF_PIPE. -
Graphics primitive pipeline :
-
DRAW_INDIRECT-
Parses indirect buffers.
-
-
COPY_INDIRECT -
INDEX_INPUT -
VERTEX_ATTRIBUTE_INPUT-
Consumes fixed function VBOs and IBOs
-
-
VERTEX_SHADER -
TESSELLATION_CONTROL_SHADER -
TESSELLATION_EVALUATION_SHADER -
GEOMETRY_SHADER -
TRANSFORM_FEEDBACK -
FRAGMENT_SHADING_RATE_ATTACHMENT -
EARLY_FRAGMENT_TESTS-
Early depth/stencil tests.
-
Render pass performs its
loadOpof a depth/stencil attachment. -
This stage isn’t all that useful or meaningful except in some very obscure scenarios with frame buffer self-dependencies (aka,
GL_ARB_texture_barrier). -
When blocking a render pass with
dstStageMask, just use a mask ofEARLY_FRAGMENT_TESTS | LATE_FRAGMENT_TESTS. -
dstStageMask = EARLY_FRAGMENT_TESTSalone might work since that will blockloadOp, but there might be shenanigans with memory barriers if you are 100% pedantic about any memory access happening inLATE_FRAGMENT_TESTS. If you’re blocking an early stage, it never hurts to block a later stage as well.
-
-
FRAGMENT_SHADER -
LATE_FRAGMENT_TESTS-
Late depth-stencil tests.
-
Render pass performs its
storeOpof a depth/stencil attachment when a render pass is done. -
When you’re waiting for a depth map to have been rendered in an earlier render pass, you should use
srcStageMask = LATE_FRAGMENT_TESTS, as that will wait for thestoreOpto finish its work.
-
-
COLOR_ATTACHMENT_OUTPUT-
This one is where
loadOp,storeOp, MSAA resolves and frame buffer blend stage takes place. -
Basically anything that touches a color attachment in a render pass in some way.
-
If you’re waiting for a render pass which uses color to be complete, use
srcStageMask = COLOR_ATTACHMENT_OUTPUT, and similar fordstStageMaskwhen blocking render passes from execution. -
Usage as
dstStageMask:-
COLOR_ATTACHMENT_OUTPUTis the appropriatedstStageMaskwhen you are transitioning an image so it can be written as a color attachment.
-
-
-
-
Graphics mesh pipeline :
-
DRAW_INDIRECT -
TASK_SHADER -
MESH_SHADER -
FRAGMENT_SHADING_RATE_ATTACHMENT -
EARLY_FRAGMENT_TESTS -
FRAGMENT_SHADER -
LATE_FRAGMENT_TESTS -
COLOR_ATTACHMENT_OUTPUT
-
-
Compute pipeline :
-
DRAW_INDIRECT -
COPY_INDIRECT -
COMPUTE_SHADER
-
-
Transfer pipeline :
-
COPY_INDIRECT -
TRANSFER
-
-
Subpass shading pipeline :
-
SUBPASS_SHADER
-
-
Graphics pipeline commands executing in a render pass with a fragment density map attachment : (almost unordered)
-
The following pipeline stage where the fragment density map read happens has no particular order relative to the other stages.
-
It is logically earlier than
EARLY_FRAGMENT_TESTS, so:-
FRAGMENT_DENSITY_PROCESS -
EARLY_FRAGMENT_TESTS
-
-
-
Conditional rendering stage : (unordered)
-
Is formally part of both the graphics, and the compute pipeline.
-
The predicate read has unspecified order relative to other stages of these pipelines:
-
CONDITIONAL_RENDERING
-
-
Host operations :
-
Only one pipeline stage occurs.
-
HOST
-
-
Command preprocessing pipeline :
-
COMMAND_PREPROCESS
-
-
Acceleration structure build operations :
-
Only one pipeline stage occurs.
-
ACCELERATION_STRUCTURE_BUILD
-
-
Acceleration structure copy operations :
-
Only one pipeline stage occurs.
-
ACCELERATION_STRUCTURE_COPY
-
-
Opacity micromap build operations :
-
Only one pipeline stage occurs.
-
MICROMAP_BUILD
-
-
Ray tracing pipeline :
-
DRAW_INDIRECT -
RAY_TRACING_SHADER
-
-
Video decode pipeline :
-
VIDEO_DECODE
-
-
Video encode pipeline :
-
VIDEO_ENCODE
-
-
Data graph pipeline :
-
DATA_GRAPH
-
Memory Access
-
Access scopes do not interact with the logically earlier or later stages for either scope - only the stages the application specifies are considered part of each access scope.
-
These flags represent memory access that can be performed.
-
Each pipeline stage can perform certain memory accesses, and thus we take the combination of pipeline stage + access mask and we get potentially a very large number of incoherent caches on the system.
-
Each GPU core has its own set of L1 caches as well.
-
Real GPUs will only have a fraction of the possible caches here, but as long as we are explicit about this in the API, any GPU driver can simplify this as needed.
-
Access masks either read from a cache, or write to an L1 cache in our mental model.
-
Certain access types are only performed by a subset of pipeline stages.
-
"Had this access (
srcAccessMask) and it's going to have this access (dstAccessMask)". -
srcAccessMask-
Lists the access types that happened before the barrier (the producer accesses) and that must be made available/visible by the barrier.
-
Must describe the kinds of accesses that actually happened before the barrier (the producer accesses you need to make available/visible) .
-
It does not describe what you want the resource to become after the barrier — that is expressed by
dstAccessMask(what will happen after). -
The stage masks (src/dst stage) specify the pipeline stages that contain those accesses.
-
srcAccessMask = 0means “there are no prior GPU memory accesses that this barrier needs to make available” (i.e. nothing to claim as the producer side).
-
-
dstAccessMask-
Lists the access types that will happen after the barrier (the consumer accesses) and that must see the producer’s writes.
-
dstAccessMask = 0means “there are no subsequent GPU memory accesses that this barrier needs to order/make visible to” (i.e. no GPU consumer to describe with access bits).
-
Access Flags
-
MEMORY_READ-
Specifies all read accesses.
-
It is always valid in any access mask, and is treated as equivalent to setting all
READaccess flags that are valid where it is used.
-
-
MEMORY_WRITE-
Specifies all write accesses.
-
It is always valid in any access mask, and is treated as equivalent to setting all
WRITEaccess flags that are valid where it is used.
-
-
SHADER_READ-
Same as
SAMPLED_READ+STORAGE_READ+TILE_ATTACHMENT_READ.
-
-
SHADER_SAMPLED_READ-
Specifies read access to a uniform texel buffer or sampled image in any shader pipeline stage.
-
-
HOST_READ-
Specifies read access by a host operation. Accesses of this type are not performed through a resource, but directly on memory.
-
Such access occurs in the
PIPELINE_STAGE_2_HOSTpipeline stage.
-
-
HOST_WRITE-
Specifies write access by a host operation. Accesses of this type are not performed through a resource, but directly on memory.
-
Such access occurs in the
PIPELINE_STAGE_2_HOSTpipeline stage.
-
Access Flag -> Pipeline Stages
| Access flag | Pipeline stages |
|-----------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
NONE
| Any |
|
INDIRECT_COMMAND_READ
|
DRAW_INDIRECT
,
ACCELERATION_STRUCTURE_BUILD
,
COPY_INDIRECT
|
|
INDEX_READ
|
VERTEX_INPUT
,
INDEX_INPUT
|
|
VERTEX_ATTRIBUTE_READ
|
VERTEX_INPUT
,
VERTEX_ATTRIBUTE_INPUT
|
|
UNIFORM_READ
|
VERTEX_SHADER
,
TESSELLATION_CONTROL_SHADER
,
TESSELLATION_EVALUATION_SHADER
,
GEOMETRY_SHADER
,
FRAGMENT_SHADER
,
COMPUTE_SHADER
,
RAY_TRACING_SHADER
,
TASK_SHADER
,
MESH_SHADER
,
SUBPASS_SHADER
,
CLUSTER_CULLING_SHADER
|
|
INPUT_ATTACHMENT_READ
|
FRAGMENT_SHADER
,
SUBPASS_SHADER
|
|
SHADER_READ
|
ACCELERATION_STRUCTURE_BUILD
,
MICROMAP_BUILD
,
VERTEX_SHADER
,
TESSELLATION_CONTROL_SHADER
,
TESSELLATION_EVALUATION_SHADER
,
GEOMETRY_SHADER
,
FRAGMENT_SHADER
,
COMPUTE_SHADER
,
RAY_TRACING_SHADER
,
TASK_SHADER
,
MESH_SHADER
,
SUBPASS_SHADER
,
CLUSTER_CULLING_SHADER
|
|
SHADER_WRITE
|
VERTEX_SHADER
,
TESSELLATION_CONTROL_SHADER
,
TESSELLATION_EVALUATION_SHADER
,
GEOMETRY_SHADER
,
FRAGMENT_SHADER
,
COMPUTE_SHADER
,
RAY_TRACING_SHADER
,
TASK_SHADER
,
MESH_SHADER
,
SUBPASS_SHADER
,
CLUSTER_CULLING_SHADER
|
|
COLOR_ATTACHMENT_READ
|
FRAGMENT_SHADER
,
COLOR_ATTACHMENT_OUTPUT
|
|
COLOR_ATTACHMENT_WRITE
|
COLOR_ATTACHMENT_OUTPUT
|
|
DEPTH_STENCIL_ATTACHMENT_READ
|
FRAGMENT_SHADER
,
EARLY_FRAGMENT_TESTS
,
LATE_FRAGMENT_TESTS
|
|
DEPTH_STENCIL_ATTACHMENT_WRITE
|
EARLY_FRAGMENT_TESTS
,
LATE_FRAGMENT_TESTS
|
|
TRANSFER_READ
|
ALL_TRANSFER
,
COPY
,
RESOLVE
,
BLIT
,
ACCELERATION_STRUCTURE_BUILD
,
ACCELERATION_STRUCTURE_COPY
,
MICROMAP_BUILD
,
CONVERT_COOPERATIVE_VECTOR_MATRIX
|
|
TRANSFER_WRITE
|
ALL_TRANSFER
,
COPY
,
RESOLVE
,
BLIT
,
CLEAR
,
ACCELERATION_STRUCTURE_BUILD
,
ACCELERATION_STRUCTURE_COPY
,
MICROMAP_BUILD
,
CONVERT_COOPERATIVE_VECTOR_MATRIX
|
|
HOST_READ
|
HOST
|
|
HOST_WRITE
|
HOST
|
|
MEMORY_READ
| Any |
|
MEMORY_WRITE
| Any |
|
SHADER_SAMPLED_READ
|
VERTEX_SHADER
,
TESSELLATION_CONTROL_SHADER
,
TESSELLATION_EVALUATION_SHADER
,
GEOMETRY_SHADER
,
FRAGMENT_SHADER
,
COMPUTE_SHADER
,
RAY_TRACING_SHADER
,
TASK_SHADER
,
MESH_SHADER
,
SUBPASS_SHADER
,
CLUSTER_CULLING_SHADER
|
|
SHADER_STORAGE_READ
|
VERTEX_SHADER
,
TESSELLATION_CONTROL_SHADER
,
TESSELLATION_EVALUATION_SHADER
,
GEOMETRY_SHADER
,
FRAGMENT_SHADER
,
COMPUTE_SHADER
,
RAY_TRACING_SHADER
,
TASK_SHADER
,
MESH_SHADER
,
SUBPASS_SHADER
,
CLUSTER_CULLING_SHADER
|
|
SHADER_STORAGE_WRITE
|
VERTEX_SHADER
,
TESSELLATION_CONTROL_SHADER
,
TESSELLATION_EVALUATION_SHADER
,
GEOMETRY_SHADER
,
FRAGMENT_SHADER
,
COMPUTE_SHADER
,
RAY_TRACING_SHADER
,
TASK_SHADER
,
MESH_SHADER
,
SUBPASS_SHADER
,
CLUSTER_CULLING_SHADER
|
|
VIDEO_DECODE_READ
|
VIDEO_DECODE
|
|
VIDEO_DECODE_WRITE
|
VIDEO_DECODE
|
|
VIDEO_ENCODE_READ
|
VIDEO_ENCODE
|
|
VIDEO_ENCODE_WRITE
|
VIDEO_ENCODE
|
|
TRANSFORM_FEEDBACK_WRITE
|
TRANSFORM_FEEDBACK
|
|
TRANSFORM_FEEDBACK_COUNTER_READ
|
DRAW_INDIRECT
,
TRANSFORM_FEEDBACK
|
|
TRANSFORM_FEEDBACK_COUNTER_WRITE
|
TRANSFORM_FEEDBACK
|
|
CONDITIONAL_RENDERING_READ
|
CONDITIONAL_RENDERING
|
|
COMMAND_PREPROCESS_READ
|
COMMAND_PREPROCESS
|
|
COMMAND_PREPROCESS_WRITE
|
COMMAND_PREPROCESS
|
|
FRAGMENT_SHADING_RATE_ATTACHMENT_READ
|
FRAGMENT_SHADING_RATE_ATTACHMENT
|
|
ACCELERATION_STRUCTURE_READ
|
VERTEX_SHADER
,
TESSELLATION_CONTROL_SHADER
,
TESSELLATION_EVALUATION_SHADER
,
GEOMETRY_SHADER
,
FRAGMENT_SHADER
,
COMPUTE_SHADER
,
RAY_TRACING_SHADER
,
TASK_SHADER
,
MESH_SHADER
,
CLUSTER_CULLING_SHADER
,
ACCELERATION_STRUCTURE_BUILD
,
ACCELERATION_STRUCTURE_COPY
,
SUBPASS_SHADER
|
|
ACCELERATION_STRUCTURE_WRITE
|
ACCELERATION_STRUCTURE_BUILD
,
ACCELERATION_STRUCTURE_COPY
|
|
FRAGMENT_DENSITY_MAP_READ
|
FRAGMENT_DENSITY_PROCESS
|
|
COLOR_ATTACHMENT_READ_NONCOHERENT
|
COLOR_ATTACHMENT_OUTPUT
|
|
DESCRIPTOR_BUFFER_READ
|
VERTEX_SHADER
,
TESSELLATION_CONTROL_SHADER
,
TESSELLATION_EVALUATION_SHADER
,
GEOMETRY_SHADER
,
FRAGMENT_SHADER
,
COMPUTE_SHADER
,
RAY_TRACING_SHADER
,
TASK_SHADER
,
MESH_SHADER
,
SUBPASS_SHADER
,
CLUSTER_CULLING_SHADER
|
|
INVOCATION_MASK_READ
|
INVOCATION_MASK
|
|
MICROMAP_READ
|
MICROMAP_BUILD
,
ACCELERATION_STRUCTURE_BUILD
|
|
MICROMAP_WRITE
|
MICROMAP_BUILD
|
|
OPTICAL_FLOW_READ
|
OPTICAL_FLOW
|
|
OPTICAL_FLOW_WRITE
|
OPTICAL_FLOW
|
|
SHADER_TILE_ATTACHMENT_READ
|
FRAGMENT_SHADER
,
COMPUTE_SHADER
|
|
SHADER_TILE_ATTACHMENT_WRITE
|
FRAGMENT_SHADER
,
COMPUTE_SHADER
|
|
DATA_GRAPH_READ
|
DATA_GRAPH
|
|
DATA_GRAPH_WRITE
|
DATA_GRAPH
|
Pipeline Stage -> Access Flags
| Pipeline stage | Access flags |
| ----------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
|
ACCELERATION_STRUCTURE_BUILD
|
ACCELERATION_STRUCTURE_READ
,
ACCELERATION_STRUCTURE_WRITE
,
INDIRECT_COMMAND_READ
,
MICROMAP_READ
,
SHADER_READ
,
TRANSFER_READ
,
TRANSFER_WRITE
|
|
ACCELERATION_STRUCTURE_COPY
|
ACCELERATION_STRUCTURE_READ
,
ACCELERATION_STRUCTURE_WRITE
,
TRANSFER_READ
,
TRANSFER_WRITE
|
|
ALL_TRANSFER
|
TRANSFER_READ
,
TRANSFER_WRITE
|
|
ANY
|
MEMORY_READ
,
MEMORY_WRITE
,
NONE
|
|
BLIT
|
TRANSFER_READ
,
TRANSFER_WRITE
|
|
CLEAR
|
TRANSFER_WRITE
|
|
CLUSTER_CULLING_SHADER
|
ACCELERATION_STRUCTURE_READ
,
DESCRIPTOR_BUFFER_READ
,
SHADER_READ
,
SHADER_SAMPLED_READ
,
SHADER_STORAGE_READ
,
SHADER_STORAGE_WRITE
,
SHADER_WRITE
,
UNIFORM_READ
|
|
COLOR_ATTACHMENT_OUTPUT
|
COLOR_ATTACHMENT_READ
,
COLOR_ATTACHMENT_READ_NONCOHERENT
,
COLOR_ATTACHMENT_WRITE
|
|
COMMAND_PREPROCESS
|
COMMAND_PREPROCESS_READ
,
COMMAND_PREPROCESS_WRITE
|
|
COMPUTE_SHADER
|
ACCELERATION_STRUCTURE_READ
,
DESCRIPTOR_BUFFER_READ
,
SHADER_READ
,
SHADER_SAMPLED_READ
,
SHADER_STORAGE_READ
,
SHADER_STORAGE_WRITE
,
SHADER_TILE_ATTACHMENT_READ
,
SHADER_TILE_ATTACHMENT_WRITE
,
SHADER_WRITE
,
UNIFORM_READ
|
|
CONDITIONAL_RENDERING
|
CONDITIONAL_RENDERING_READ
|
|
CONVERT_COOPERATIVE_VECTOR_MATRIX
|
TRANSFER_READ
,
TRANSFER_WRITE
|
|
COPY
|
TRANSFER_READ
,
TRANSFER_WRITE
|
|
COPY_INDIRECT
|
INDIRECT_COMMAND_READ
|
|
DATA_GRAPH
|
DATA_GRAPH_READ
,
DATA_GRAPH_WRITE
|
|
DRAW_INDIRECT
|
INDIRECT_COMMAND_READ
,
TRANSFORM_FEEDBACK_COUNTER_READ
|
|
EARLY_FRAGMENT_TESTS
|
DEPTH_STENCIL_ATTACHMENT_READ
,
DEPTH_STENCIL_ATTACHMENT_WRITE
|
|
FRAGMENT_DENSITY_PROCESS
|
FRAGMENT_DENSITY_MAP_READ
|
|
FRAGMENT_SHADER
|
ACCELERATION_STRUCTURE_READ
,
COLOR_ATTACHMENT_READ
,
DEPTH_STENCIL_ATTACHMENT_READ
,
DESCRIPTOR_BUFFER_READ
,
INPUT_ATTACHMENT_READ
,
SHADER_READ
,
SHADER_SAMPLED_READ
,
SHADER_STORAGE_READ
,
SHADER_STORAGE_WRITE
,
SHADER_TILE_ATTACHMENT_READ
,
SHADER_TILE_ATTACHMENT_WRITE
,
SHADER_WRITE
,
UNIFORM_READ
|
|
FRAGMENT_SHADING_RATE_ATTACHMENT
|
FRAGMENT_SHADING_RATE_ATTACHMENT_READ
|
|
GEOMETRY_SHADER
|
ACCELERATION_STRUCTURE_READ
,
DESCRIPTOR_BUFFER_READ
,
SHADER_READ
,
SHADER_SAMPLED_READ
,
SHADER_STORAGE_READ
,
SHADER_STORAGE_WRITE
,
SHADER_WRITE
,
UNIFORM_READ
|
|
HOST
|
HOST_READ
,
HOST_WRITE
|
|
INDEX_INPUT
|
INDEX_READ
|
|
INVOCATION_MASK
|
INVOCATION_MASK_READ
|
|
LATE_FRAGMENT_TESTS
|
DEPTH_STENCIL_ATTACHMENT_READ
,
DEPTH_STENCIL_ATTACHMENT_WRITE
|
|
MESH_SHADER
|
ACCELERATION_STRUCTURE_READ
,
DESCRIPTOR_BUFFER_READ
,
SHADER_READ
,
SHADER_SAMPLED_READ
,
SHADER_STORAGE_READ
,
SHADER_STORAGE_WRITE
,
SHADER_WRITE
,
UNIFORM_READ
|
|
MICROMAP_BUILD
|
MICROMAP_READ
,
MICROMAP_WRITE
,
SHADER_READ
,
TRANSFER_READ
,
TRANSFER_WRITE
|
|
OPTICAL_FLOW
|
OPTICAL_FLOW_READ
,
OPTICAL_FLOW_WRITE
|
|
RAY_TRACING_SHADER
|
ACCELERATION_STRUCTURE_READ
,
DESCRIPTOR_BUFFER_READ
,
SHADER_READ
,
SHADER_SAMPLED_READ
,
SHADER_STORAGE_READ
,
SHADER_STORAGE_WRITE
,
SHADER_WRITE
,
UNIFORM_READ
|
|
RESOLVE
|
TRANSFER_READ
,
TRANSFER_WRITE
|
|
SUBPASS_SHADER
|
ACCELERATION_STRUCTURE_READ
,
DESCRIPTOR_BUFFER_READ
,
INPUT_ATTACHMENT_READ
,
SHADER_READ
,
SHADER_SAMPLED_READ
,
SHADER_STORAGE_READ
,
SHADER_STORAGE_WRITE
,
SHADER_WRITE
,
UNIFORM_READ
|
|
TASK_SHADER
|
ACCELERATION_STRUCTURE_READ
,
DESCRIPTOR_BUFFER_READ
,
SHADER_READ
,
SHADER_SAMPLED_READ
,
SHADER_STORAGE_READ
,
SHADER_STORAGE_WRITE
,
SHADER_WRITE
,
UNIFORM_READ
|
|
TESSELLATION_CONTROL_SHADER
|
ACCELERATION_STRUCTURE_READ
,
DESCRIPTOR_BUFFER_READ
,
SHADER_READ
,
SHADER_SAMPLED_READ
,
SHADER_STORAGE_READ
,
SHADER_STORAGE_WRITE
,
SHADER_WRITE
,
UNIFORM_READ
|
|
TESSELLATION_EVALUATION_SHADER
|
ACCELERATION_STRUCTURE_READ
,
DESCRIPTOR_BUFFER_READ
,
SHADER_READ
,
SHADER_SAMPLED_READ
,
SHADER_STORAGE_READ
,
SHADER_STORAGE_WRITE
,
SHADER_WRITE
,
UNIFORM_READ
|
|
TRANSFORM_FEEDBACK
|
TRANSFORM_FEEDBACK_COUNTER_READ
,
TRANSFORM_FEEDBACK_COUNTER_WRITE
,
TRANSFORM_FEEDBACK_WRITE
|
|
VERTEX_ATTRIBUTE_INPUT
|
VERTEX_ATTRIBUTE_READ
|
|
VERTEX_INPUT
|
INDEX_READ
,
VERTEX_ATTRIBUTE_READ
|
|
VERTEX_SHADER
|
ACCELERATION_STRUCTURE_READ
,
DESCRIPTOR_BUFFER_READ
,
SHADER_READ
,
SHADER_SAMPLED_READ
,
SHADER_STORAGE_READ
,
SHADER_STORAGE_WRITE
,
SHADER_WRITE
,
UNIFORM_READ
|
|
VIDEO_DECODE
|
VIDEO_DECODE_READ
,
VIDEO_DECODE_WRITE
|
|
VIDEO_ENCODE
|
VIDEO_ENCODE_READ
,
VIDEO_ENCODE_WRITE
|
Pipeline Barriers
-
Pipeline barriers also provide synchronization control within a command buffer, but at a single point, rather than with separate signal and wait operations. Pipeline barriers can be used to control resource access within a single queue.
-
Gives control over which pipeline stages need to wait on previous pipeline stages when a command buffer is executed.
-
Nvidia: Minimize the use of barriers. A barrier may cause a GPU pipeline flush. We have seen redundant barriers and associated wait for idle operations as a major performance problem for ports to modern APIs.
-
Nvidia: Prefer a buffer/image barrier rather than a memory barrier to allow the driver to better optimize and schedule the barrier, unless the memory barrier allows to merge many buffer/image barriers together.
-
Nvidia: Group barriers in one call to
vkCmdPipelineBarrier2(). This way, the worst case can be picked instead of sequentially going through all barriers. -
Nvidia: Don’t insert redundant barriers; this limits parallelism; avoid read-to-read barriers.
-
-
When submitted to a queue, it defines memory dependencies between commands that were submitted to the same queue before it, and those submitted to the same queue after it.
-
commandBuffer-
Is the command buffer into which the command is recorded.
-
-
pDependencyInfo-
Specifies the dependency information for a synchronization command.
-
This structure defines a set of memory dependencies , as well as queue family ownership transfer operations and image layout transitions .
-
Each member of
pMemoryBarriers,pBufferMemoryBarriers, andpImageMemoryBarriersdefines a separate memory dependency . -
dependencyFlags-
Specifies how execution and memory dependencies are formed.
-
DEPENDENCY_BY_REGION-
Specifies that dependencies will be framebuffer-local .
-
-
DEPENDENCY_VIEW_LOCAL-
Specifies that dependencies will be view-local .
-
-
DEPENDENCY_DEVICE_GROUP-
Specifies that dependencies are non-device-local .
-
-
DEPENDENCY_FEEDBACK_LOOP_EXT-
Specifies that the render pass will write to and read from the same image with feedback loop enabled .
-
-
DEPENDENCY_QUEUE_FAMILY_OWNERSHIP_TRANSFER_USE_ALL_STAGES_KHR-
Specifies that source and destination stages are not ignored when performing a queue family ownership transfer .
-
-
DEPENDENCY_ASYMMETRIC_EVENT_KHR-
Specifies that vkCmdSetEvent2 must only include the source stage mask of the first synchronization scope, and that vkCmdWaitEvents2 must specify the complete barrier.
-
-
memoryBarrierCount-
Is the length of the
pMemoryBarriersarray.
-
-
pMemoryBarriers-
Specifies a global memory barrier.
-
srcStageMask -
srcAccessMask -
dstStageMask -
dstAccessMask
-
bufferMemoryBarrierCount-
Is the length of the
pBufferMemoryBarriersarray.
-
-
pBufferMemoryBarriers-
Specifies a buffer memory barrier.
-
Defines a memory dependency limited to a range of a buffer, and can define a queue family ownership transfer operation for that range.
-
Both access scopes are limited to only memory accesses to
bufferin the range defined byoffsetandsize. -
srcStageMask -
srcAccessMask -
dstStageMask -
dstAccessMask -
srcQueueFamilyIndex -
dstQueueFamilyIndex -
buffer-
Is a handle to the buffer whose backing memory is affected by the barrier.
-
-
offset-
Is an offset in bytes into the backing memory for
buffer; this is relative to the base offset as bound to the buffer (see vkBindBufferMemory ).
-
-
size-
Is a size in bytes of the affected area of backing memory for
buffer, orWHOLE_SIZEto use the range fromoffsetto the end of the buffer.
-
-
imageMemoryBarrierCount-
Is the length of the
pImageMemoryBarriersarray.
-
-
pImageMemoryBarriers-
Specifies an image memory barrier.
-
Defines a memory dependency limited to an image subresource range, and can define a queue family ownership transfer operation and image layout transition for that subresource range.
-
Image Transition :
-
If
oldLayoutis not equal tonewLayout, then the memory barrier defines an image layout transition for the specified image subresource range. -
If this memory barrier defines a queue family ownership transfer operation , the layout transition is only executed once between the queues.
-
When the old and new layout are equal, the layout values are ignored - data is preserved no matter what values are specified, or what layout the image is currently in.
-
-
srcStageMask -
srcAccessMask -
dstStageMask -
dstAccessMask -
srcQueueFamilyIndex -
dstQueueFamilyIndex -
oldLayout -
newLayout -
image-
Is a handle to the image affected by this barrier.
-
-
subresourceRange-
Describes the image subresource range within
imagethat is affected by this barrier.
-
-
Execution Barrier
-
Every command you submit to Vulkan goes through a set of stages. Draw calls, copy commands and compute dispatches all go through pipeline stages one by one. This represents the heart of the Vulkan synchronization model.
-
Operations performed by synchronization commands (e.g. availability operations and visibility operations ) are not executed by a defined pipeline stage. However other commands can still synchronize with them by using the synchronization scopes to create a dependency chain.
-
When we synchronize work in Vulkan, we synchronize work happening in these pipeline stages as a whole, and not individual commands of work.
-
Vulkan does not let you add fine-grained dependencies between individual commands. Instead you get to look at all work which happens in certain pipeline stages.
Memory Barriers
-
Execution order and memory order are two different things.
-
Memory barriers are the tools we can use to ensure that caches are flushed and our memory writes from commands executed before the barrier are available to the pending after-barrier commands. They are also the tool we can use to invalidate caches so that the latest data is visible to the cores that will execute after-barrier commands.
-
In contrast to execution barriers, these access masks only apply to the precise stages set in the stage masks, and are not extended to logically earlier and later stages.
-
GPUs are notorious for having multiple, incoherent caches which all need to be carefully managed to avoid glitched out rendering.
-
This means that just synchronizing execution alone is not enough to ensure that different units on the GPU can transfer data between themselves.
-
Memory being available and memory being visible are an abstraction over the fact that GPUs have incoherent caches.
-
For GPU reading operations from CPU-written data, a call to
vkQueueSubmitacts as a host memory dependency on any CPU writes to GPU-accessible memory, so long as those writes were made prior to the function call. -
If you need more fine-grained write dependency (you want the GPU to be able to execute some stuff in a batch while you're writing data, for example), or if you need to read data written by the GPU, you need an explicit dependency.
-
For in-batch GPU reading, this could be handled by an event; the host sets the event after writing the memory, and the command buffer operation that reads the memory first issues
vkCmdWaitEventsfor that event. And you'll need to set the appropriate memory barriers and source/destination stages. -
For CPU reading of GPU-written data, this could be an event, a timeline semaphore, or a fence.
-
But overall, CPU writes to GPU-accessible memory still need some form of synchronization.
Global Memory Barriers
-
A global memory barrier deals with access to any resource, and it’s the simplest form of a memory barrier.
-
In
vkCmdPipelineBarrier2, we are specifying 4 things to happen in order:-
Wait for
srcStageMaskto complete -
Make all writes performed in possible combinations of
srcStageMask+srcAccessMaskavailable -
Make available memory visible to possible combinations of
dstStageMask+dstAccessMask. -
Unblock work in dstStageMask.
-
-
A common misconception I see is that
_READflags are passed intosrcAccessMask, but this is redundant .-
It does not make sense to make reads available.
-
Ex : you don’t flush caches when you’re done reading data.
-
Buffer Memory Barrier
-
We’re just restricting memory availability and visibility to a specific buffer.
-
TheMaister: No GPU I know of actually cares, I think it makes more sense to just use VkMemoryBarrier rather than bothering with buffer barriers.
Image Memory Barrier / Image Layout Transition
-
Image subresources can be transitioned from one layout to another as part of a memory dependency (e.g. by using an image memory barrier ).
-
Image layouts transitions are done as part of an image memory barrier.
-
The layout transition happens in-between the make available and make visible stages of a memory barrier.
-
The layout transition itself is considered a read/write operation, and the rules are basically that memory for the image must be available before the layout transition takes place.
-
After a layout transition, that memory is automatically made available (but not visible !).
-
Basically, think of the layout transition as some kind of in-place data munging which happens in L2 cache somehow.
-
How :
-
If a layout transition is specified in a memory dependency.
-
-
When :
-
It happens-after the availability operations in the memory dependency, and happens-before the visibility operations.
-
Layout transitions that are performed via image memory barriers execute in their entirety in submission order , relative to other image layout transitions submitted to the same queue, including those performed by render passes.
-
This ordering of image layout transitions only applies if the implementation performs actual read/write operations during the transition.
-
An application must not rely on ordering of image layout transitions to influence ordering of other commands.
-
-
Ensure :
-
Image layout transitions may perform read and write accesses on all memory bound to the image subresource range, so applications must ensure that all memory writes have been made available before a layout transition is executed.
-
-
Available memory is automatically made visible to a layout transition, and writes performed by a layout transition are automatically made available .
Old Layout
-
The old layout must either be
UNDEFINED, or match the current layout of the image subresource range.-
If the old layout matches the current layout of the image subresource range, the transition preserves the contents of that range.
-
If the old layout is
UNDEFINED, the contents of that range may be discarded. This can provide performance or power benefits.-
Nvidia: Use
UNDEFINEDwhen the previous content of the image is not needed.
-
-
-
Tile-based architectures may be able to avoid flushing tile data to memory, and immediate style renderers may be able to achieve fast metadata clears to reinitialize frame buffer compression state, or similar.
-
If the contents of an attachment are not needed after a render pass completes, then applications should use
DONT_CARE. -
Why Need the Old Layout in Vulkan Image Transitions .
-
Cool.
-
Recently allocated image
-
If we just allocated an image and want to start using it, what we want to do is to just perform a layout transition, but we don’t need to wait for anything in order to do this transition.
-
It’s important to note that freshly allocated memory in Vulkan is always considered available and visible to all stages and access types. You cannot have stale caches when the memory was never accessed.
Events / "Split Barriers"
-
A way to get overlapping work in-between barriers.
-
The idea of
VkEventis to get some unrelated commands in-between the “before” and “after” set of commands -
For advanced compute, this is a very important thing to know about, but not all GPUs and drivers can take advantage of this feature.
-
Nvidia: Use
vkCmdSetEvent2andvkCmdWaitEvents2to issue an asynchronous barrier to avoid blocking execution.
Example
-
Example 1 :
-
vkCmdDispatch -
vkCmdDispatch -
vkCmdSetEvent(event, srcStageMask = COMPUTE) -
vkCmdDispatch -
vkCmdWaitEvent(event, dstStageMask = COMPUTE) -
vkCmdDispatch -
vkCmdDispatch
-
The " before " set is now {
1,2}, and the " after " set is {6,7}. -
4here is not affected by any synchronization and it can fill in the parallelism “bubble” we get when draining the GPU of work from1,2,3.
-
-
 .
.
Semaphores and Fences
-
These objects are signaled as part of a
vkQueueSubmit. -
To signal a semaphore or fence, all previously submitted commands to the queue must complete.
-
If this were a regular pipeline barrier, we would have
srcStageMask = ALL_COMMANDS. However, we also get a full memory barrier, in the sense that all pending writes are made available. Essentially,srcAccessMask = MEMORY_WRITE. -
Signaling a fence or semaphore works like a full cache flush. Submitting commands to the Vulkan queue makes all memory access performed by host visible to all stages and access masks. Basically, submitting a batch issues a cache invalidation on host visible memory.
-
A common mistake is to think that you need to do this invalidation manually when the CPU is writing into staging buffers or similar:
-
srcStageMask = HOST -
dstStageMask = TRANSFER -
srcAccessMask = HOST_WRITE -
dstAccessMask = TRANSFER_READ -
If the write happened before
vkQueueSubmit, this is automatically done for you. -
This kind of barrier is necessary if you are using
vkCmdWaitEventswhere you wait for host to signal the event withvkSetEvent. In that case, you might be writing the necessary host data aftervkQueueSubmitwas called, which means you need a pipeline barrier like this. This is not exactly a common use case, but it’s important to understand when these API constructs are useful.
-
Semaphore
-
VkSemaphore -
Semaphores facilitate GPU <-> GPU synchronization across Vulkan queues.
-
Used for syncing multiple command buffer submissions one after other.
-
The CPU continues running without blocking.
-
-
Implicit memory guarantees when waiting for a Semaphore :
-
While signalling a semaphore makes all memory available , waiting for a semaphore makes memory visible .
-
This basically means you do not need a memory barrier if you use synchronization with semaphores since signal/wait pairs of semaphores works like a full memory barrier.
-
Example :
-
Queue 1 writes to an SSBO in compute, and consumes that buffer as a UBO in a fragment shader in queue 2.
-
We’re going to assume the buffer was created with
QUEUE_FAMILY_CONCURRENT. -
Queue 1
-
vkCmdDispatch -
vkQueueSubmit(signal = my_semaphore) -
There is no pipeline barrier needed here.
-
Signalling the semaphore waits for all commands, and all writes in the dispatch are made available to the device before the semaphore is actually signaled.
-
-
Queue 2
-
vkCmdBeginRenderPass -
vkCmdDraw -
vkCmdEndRenderPass -
vkQueueSubmit(wait = my_semaphore, pDstWaitStageMask = FRAGMENT_SHADER) -
When we wait for the semaphore, we specify which stages should wait for this semaphore, in this case the
FRAGMENT_SHADERstage. -
All relevant memory access is automatically made visible , so we can safely access
UNIFORM_READinFRAGMENT_SHADERstage, without having extra barriers. -
The semaphores take care of this automatically, nice!
-
-
-
-
Examples :
-
Basic signaling / waiting :
-
Let’s say we have semaphore S and queue operations A and B that we want to execute in order.
-
What we tell Vulkan is that operation A will 'signal' semaphore S when it finishes executing, and operation B will 'wait' on semaphore S before it begins executing.
-
When operation A finishes, semaphore S will be signaled, while operation B wont start until S is signaled.
-
After operation B begins executing, semaphore S is automatically reset back to being unsignaled, allowing it to be used again.
-
-
Image Transition on Swapchain Images :
-
We need to wait for the image to be acquired, and only then can we perform a layout transition.
-
The best way to do this is to use
pDstWaitStageMask = COLOR_ATTACHMENT_OUTPUT, and then usesrcStageMask = COLOR_ATTACHMENT_OUTPUTin a pipeline barrier which transitions the swapchain image after semaphore is signaled.
-
-
-
Types of Semaphores :
-
Binary Semaphores :
-
A binary semaphore is either unsignaled or signaled.
-
It begins life as unsignaled.
-
The way we use a binary semaphore to order queue operations is by providing the same semaphore as a 'signal' semaphore in one queue operation and as a 'wait' semaphore in another queue operation.
-
Only binary semaphores will be used in this tutorial, further mention of the term semaphore exclusively refers to binary semaphores.
-
-
Timeline Semaphores :
-
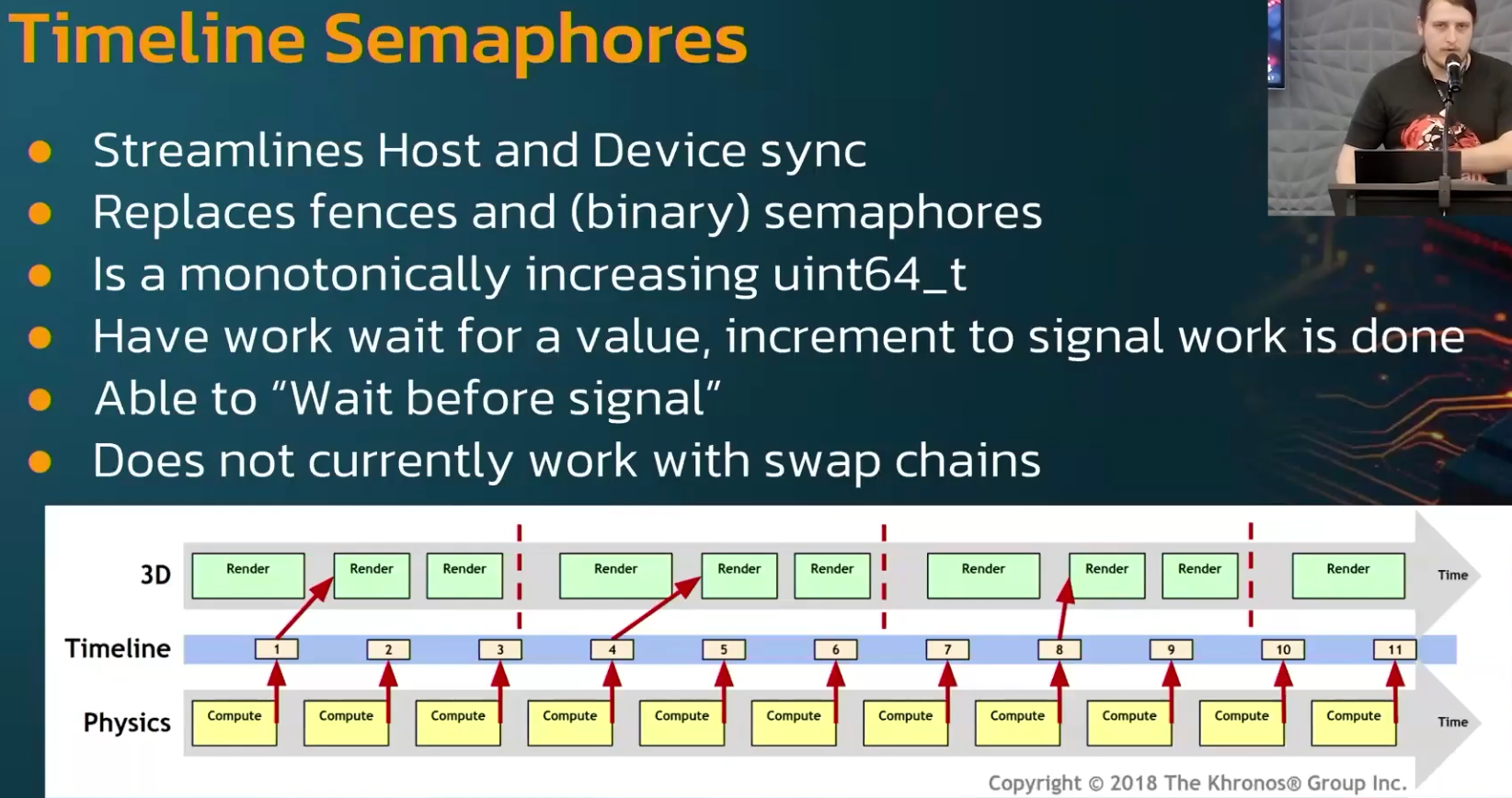 .
.
-
-
-
Correctly using the Semaphore for
vkQueuePresent:-
Since Vulkan SDK 1.4.313 , the validation layer reports cases where the present wait semaphore is not used safely:
-
This is currently reported as
VUID-vkQueueSubmit-pSignalSemaphores-00067or you may see "your VkSemaphore is being signaled by VkQueue, but it may still be in use by VkSwapchainKHR"
-
-
In this context, safely means that the Vulkan specification guarantees the semaphore is no longer in use and can be reused.
-
The problem :
-
vkQueuePresentKHRis different from thevkQueueSubmitfamily of functions in that it does not provide a way to signal a semaphore or a fence (without additional extensions). -
This means there is no way to wait for the presentation signal directly. It also means we don’t know whether
VkPresentInfoKHR::pWaitSemaphoresare still in use by the presentation operation. -
If
vkQueuePresentKHRcould signal, then waiting on that signal would confirm that the present queue operation has finished — including the wait onVkPresentInfoKHR::pWaitSemaphores. -
In summary, it’s not obvious when it’s safe to reuse present wait semaphores.
-
The Vulkan specification does not guarantee that waiting on a
vkQueueSubmitfence also synchronizes presentation operations.
-
-
The reuse of presentation resources should rely on
vkAcquireNextImageKHRor additional extensions, rather than onvkQueueSubmitfences. -
Solution options :
-
Allocate one "submit finished" semaphore per swapchain image instead of per in-flight frame.
-
Allocate the
submit_semaphoresarray based on the number of swapchain images (instead of the number of in-flight frames) -
Index this array using the acquired swapchain image index (instead of the current in-flight frame index)
-
-
Using
EXT_swapchain_maintenance1.-
See Vulkan#Recreating , for use with the swapchain.
-
-
Fences
-
VkFence -
Fences facilitate GPU -> CPU synchronization.
-
Used to know if a command buffer has finished being executed on the GPU.
-
-
While signalling a fence makes all memory available, it does not make them available to the CPU, just within the device. This is where
dstStageMask = PIPELINE_STAGE_HOSTanddstAccessMask = ACCESS_HOST_READflags come in. If you intend to read back data to the CPU, you must issue a pipeline barrier which makes memory available to the HOST as well. -
In our mental model, we can think of this as flushing the GPU L2 cache out to GPU main memory, so that CPU can access it over some bus interface.
-
In order to signal that fence, any pending writes to that memory must have been made available, so even recycled memory can be safely reused without a memory barrier. This point is kind of subtle, but it really helps your sanity not having to inject memory barriers everywhere.
-
Usage :
-
Similar to semaphores, fences are either in a signaled or unsignaled state.
-
Whenever we submit work to execute, we can attach a fence to that work. When the work is finished, the fence will be signaled.
-
Then we can make the CPU wait for the fence to be signaled, guaranteeing that the work has finished before the CPU continues.
-
Fences must be reset manually to put them back into the unsignaled state.
-
This is because fences are used to control the execution of the CPU, and so the CPU gets to decide when to reset the fence.
-
Contrast this to semaphores which are used to order work on the GPU without the CPU being involved.
-
-
Unlike the semaphore, the fence does block CPU execution.
-
In general, it is preferable to not block the host unless necessary.
-
We want to feed the GPU and the host with useful work to do. Waiting on fences to signal is not useful work.
-
Thus, we prefer semaphores, or other synchronization primitives not yet covered, to synchronize our work.
-
-
-
Example :
-
Taking a screenshot :
-
Once we have already done the necessary work on the GPU, we now need to transfer the image from the GPU over to the host and then save the memory to a file.
-
We have command buffer A which executes the transfer and fence F. We submit command buffer A with fence F, then immediately tell the host to wait for F to signal. This causes the host to block until command buffer A finishes execution.
-
Thus, we are safe to let the host save the file to disk, as the memory transfer has completed.
-
Unlike the semaphore example, this example does block host execution. This means the host won’t do anything except wait until the execution has finished. For this case, we had to make sure the transfer was complete before we could save the screenshot to disk.
-
-
Main Loop Synchronization
-

-
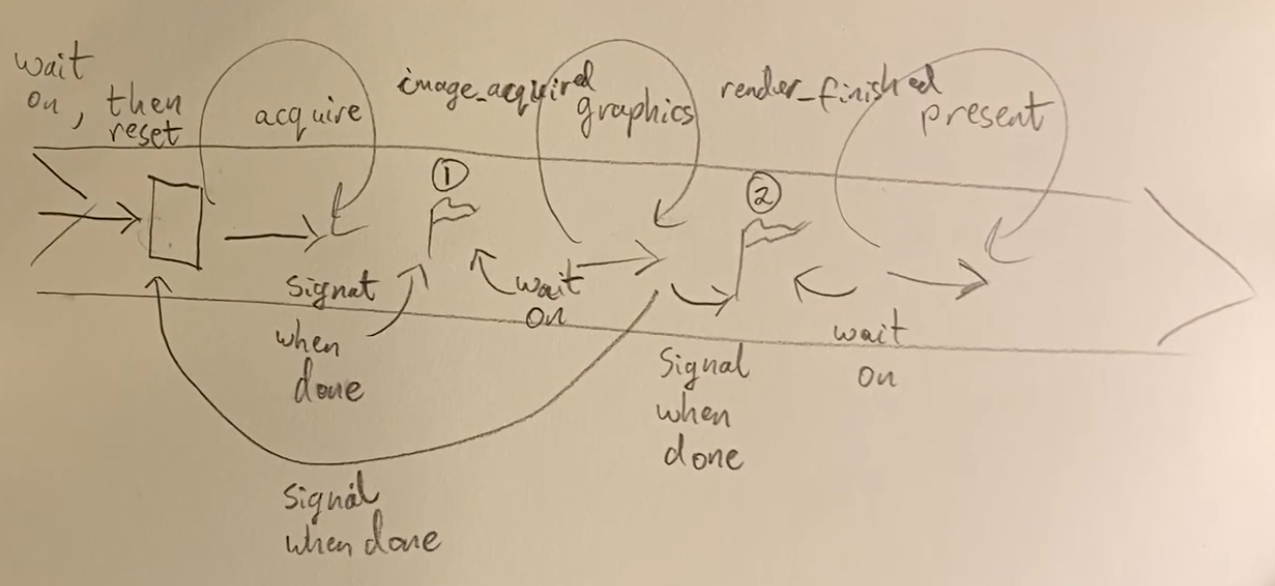 .
.
-
-
The entire video is just drawings.
-
-
-
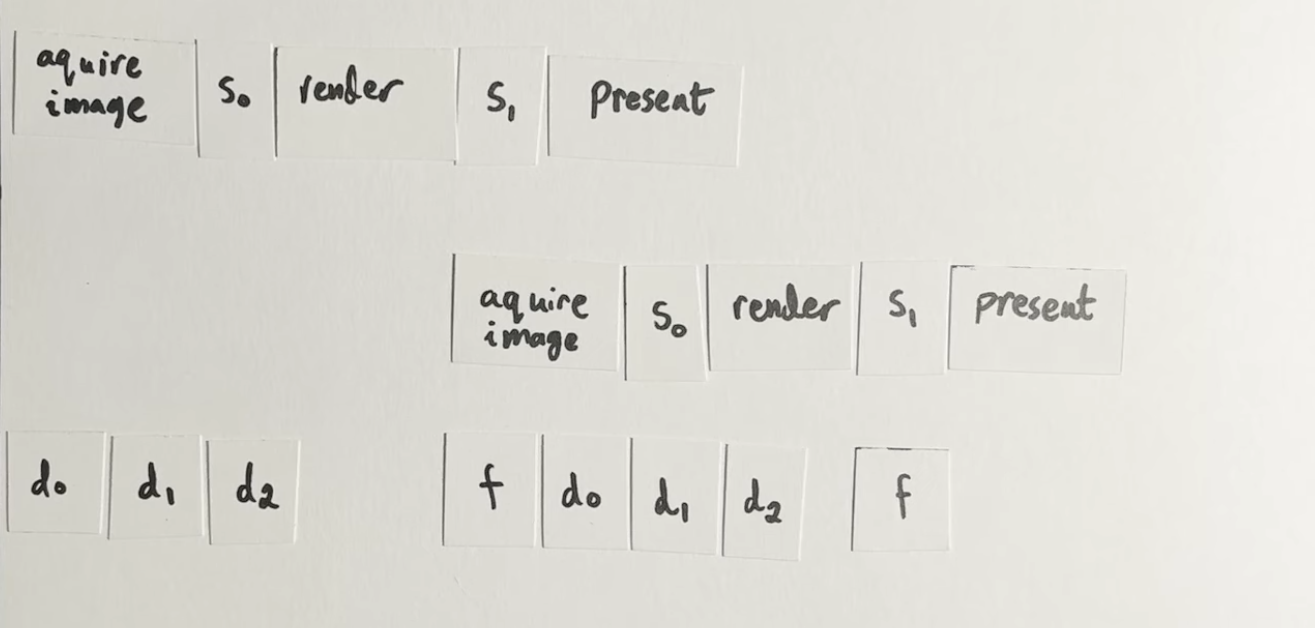 .
.
-
-
Good illustration.
-
The rest of the video is just code.
-
Does not comment on Multiple Frames In Flight.
-
-