Shader Alignment
Minimum Dynamic-Offset / CBV Allocation Granularity
-
GPUs and drivers require that when you bind or use a portion of a large buffer as a uniform/constant buffer the start address and/or size line up to an alignment.
-
That alignment is the “minimum dynamic-offset” (Vulkan) or the CBV/constant buffer granularity (D3D12).
-
It lets the driver map many small logical buffers into a single big GPU buffer efficiently.
-
If you bind at an unaligned offset the API/driver will reject it or you will get wrong data or degraded performance.
-
Drivers can report 64, 128, 256, or other powers of two.
-
UBO alignment is usually larger than SSBO alignment because UBO usage and caches are handled differently by the hardware.
-
Value :
-
Many APIs and drivers use 256 bytes as the Minimum Dynamic-Offset on common desktop GPUs.
-
VkGuide:
struct MaterialConstants { // written into uniform buffers later glm::vec4 colorFactors; // multiply the color texture glm::vec4 metal_rough_factors; glm::vec4 extra[14]; /* padding, we need it anyway for uniform buffers it needs to meet a minimum requirement for its alignment. 256 bytes is a good default alignment for this which all the gpus we target meet, so we are adding those vec4s to pad the structure to 256 bytes. */ }; -
-
But not every platform or GPU guarantees 256. Mobile or integrated GPUs may have different values.
-
-
minUniformBufferOffsetAlignment-
Is the minimum required alignment, in bytes, for the
offsetmember of theVkDescriptorBufferInfostructure for uniform buffers. -
When a descriptor of type
DESCRIPTOR_TYPE_UNIFORM_BUFFERorDESCRIPTOR_TYPE_UNIFORM_BUFFER_DYNAMICis updated, theoffsetmust be an integer multiple of this limit. -
Similarly, dynamic offsets for uniform buffers must be multiples of this limit.
-
The value must be a power of two.
-
-
minStorageBufferOffsetAlignment-
Is the minimum required alignment, in bytes, for the
offsetmember of theVkDescriptorBufferInfostructure for storage buffers. -
When a descriptor of type
DESCRIPTOR_TYPE_STORAGE_BUFFERorDESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMICis updated, theoffsetmust be an integer multiple of this limit. -
Similarly, dynamic offsets for storage buffers must be multiples of this limit.
-
The value must be a power of two.
-
-
minTexelBufferOffsetAlignment-
Is the minimum required alignment, in bytes, for the
offsetmember of the VkBufferViewCreateInfo structure for texel buffers. -
If the
texelBufferAlignmentfeature is enabled, this limit is equivalent to the maximum of theuniformTexelBufferOffsetAlignmentBytesandstorageTexelBufferOffsetAlignmentBytesmembers of VkPhysicalDeviceTexelBufferAlignmentProperties , but smaller alignment is optionally allowed bystorageTexelBufferOffsetSingleTexelAlignmentanduniformTexelBufferOffsetSingleTexelAlignment. -
If the
texelBufferAlignmentfeature is not enabled, VkBufferViewCreateInfo ::offsetmust be a multiple of this value. -
The value must be a power of two.
-
-
-
-
Best practice :
-
Query the GPU at runtime and align your buffer ranges to the reported value.
-
Assert size at compile time:
static_assert(sizeof(MaterialConstants) == 256, "MaterialConstants must be 256 bytes"); -
Default Layouts
-
UBOs :
-
std140.
-
-
SSBOs :
-
std430.
-
-
Push Constants :
-
std430 (Vulkan).
-
Source: GLSL Spec 4.60.8 , page 90.
-
OpenGL Spec 4.6 , page 146 (7.6.2.2).
-
-
Alignment Options
-
There are different alignment requirements depending on the specific resources and on the features enabled.
-
Platform dependency :
-
32-bit IEEE-754
-
The scalar value is 4 bytes.
-
The standard for desktop, mobile, OpenGL ES and Vulkan.
-
-
16-bit half precision :
-
The scalar value is 2 bytes.
-
In rare cases, like embedded or custom OpenGL drivers.
-
-
64-bit IEEE-754 double :
-
The scalar value is 8 bytes.
-
Non-standard case.
-
Would require headers redefining
GLfloatasdouble, not compliant with spec.
-
-
-
C layout ≈
std430only if you manually match packing and alignment. Otherwise, it’s platform-dependent.
| GLSL type | C equivalent | Typical C (x86_64) - Alignment | Typical C (x86_64) - Size | Typical C (x86_64) - Stride | std140 - Base Alignment | std140 - Occupied Size | std140 - Stride | std430 - Base Alignment | std430 - Occupied Size | std430 - Stride |
| -------------------------------- | --------------------------------------------------- | -----------------------------: | -----------------------------------: | --------------------------: | -----------------------------------------------------------------------------------------: | ------------------------------------: | ---------------------------------------: | ----------------------: | ----------------------------------------------------: | ------------------------------------------: |
|
bool
| C
_Bool
(native) — or use
int32_t
to match GLSL |
_Bool
: 1;
int32_t
: 4 |
_Bool
: 1;
int32_t
: 4 |
_Bool
: 1;
int32_t
: 4 | 4 | 4 | 16 (std140 rounds scalar arrays to vec4) | 4 | 4 | 4 |
|
int
/
uint
|
int32_t
/
uint32_t
| 4 | 4 | 4 | 4 | 4 | 16 | 4 | 4 | 4 |
|
float
|
float
| 4 | 4 | 4 | 4 | 4 | 16 | 4 | 4 | 4 |
|
double
|
double
| 8 | 8 | 8 | 8 | 8 | 32 (rounded to dvec4 alignment) | 8 | 8 | 8 |
|
vec2
/
ivec2
|
float[2]
/
int32_t[2]
| 4 | 8 | 8 | 8 | 8 | 16 | 8 | 8 | 8 |
|
vec3
/
ivec3
|
float[3]
/
int32_t[3]
| 4 | 12 | 12 | 16 | 16 | 16 | 16 | 16 | 16 |
|
vec4
/
ivec4
|
float[4]
/
int32_t[4]
| 4 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
|
dvec2
|
double[2]
| 8 | 16 | 16 | 16 | 16 | 32 | 16 | 16 | 16 |
|
dvec3
|
double[3]
| 8 | 24 | 24 | 32 | 32 | 32 | 32 | 32 | 32 |
|
dvec4
|
double[4]
| 8 | 32 | 32 | 32 | 32 | 32 | 32 | 32 | 32 |
|
mat2
(2×2 float, column-major) |
float[2][2]
(2 columns of
vec2
) | 4 | 16 | 8 (column size) | 16 | 16 × 2 = 32 | each column has vec4 as stride (16) | 8 | 8 × 2 = 16 | each column has vec2 as stride (8) |
|
mat3
(3×3 float, column-major) |
float[3][3]
(3 columns of
vec3
) | 4 | 36 | 12 (column size) | 16 | 16 × 3 = 48 | each column has vec4 as stride (16) | 16 | 16 × 3 = 48 | each column has vec3 as stride (16) |
|
mat4
(4×4 float) |
float[4][4]
| 4 | 64 | 16 (column size) | 16 | 16 x 4 = 64 | each column has vec4 as stride (16) | 16 | 16 × 4 = 64 | each column has vec4 as stride (16) |
|
T[]
(Array of T) |
T[]
| alignof(T) | sizeof(T) | sizeof(T) | base_align(T), rounded up to vec4 base align (16 for 32-bit scalars; 32 for 64-bit/double) | occupied per element = rounded stride | base_align(T), rounded up to 16 | base_align(T) | occupied per element = sizeof(T) rounded to alignment | base_align(T) |
|
vec3[]
(Array of vec3) |
float[3][]
| 4 | 12 | 12 | 16 | 16 | 16 | 16 | 16 | 16 |
|
struct
|
struct { ... }
| max(member alignment) | struct size padded to that alignment | sizeof(struct) (padded) | max(member align) rounded up to vec4 (16) | struct size padded to multiple of 16 | sizeof(struct) rounded up to 16 | max(member align) | struct size padded to that alignment | sizeof(struct) (padded to member alignment) |
Scalar Alignment
-
Looks like std430 , but its vectors are even more compact?
-
Also known as (?) The spec doesn't say.
-
-
Core in Vulkan 1.2.
-
This extension allows most storage types to be aligned in
scalaralignment. -
Make sure to set
--scalar-block-layoutwhen running the SPIR-V Validator. -
A big difference is being able to straddle the 16-byte boundary.
-
In GLSL this can be used with
scalarkeyword and extension
-
Extended Alignment (std140)
-
Source .
-
Conservative, padded layout used for uniform blocks.
-
Widely supported.
-
Caveats :
-
"Avoiding usage of vec3"
-
Usually applies to std140, because some hardware vendors seem to not follow the spec strictly. Although, everything should work when using std430.
-
Array of
vec3(ARRAY) :-
Alignment will be 4x of a
float. -
Size will be
alignment * amount of elements.
-
-
-
// Scalars
float -> 4 bytes // for 32-bit IEEE-754
int -> 4 bytes // for 32-bit IEEE-754
uint -> 4 bytes // for 32-bit IEEE-754
bool -> 4 bytes // for 32-bit IEEE-754
// Vectors
// Base alignments
vec2 -> 8 bytes // 2 times the underlying scalar type.
vec3 -> 16 bytes // 4 times the underlying scalar type.
vec4 -> 16 bytes // 4 times the underlying scalar type.
// Arrays
// Size of the element type, rounded up to a multiple of the size of `vec4` (behave like `vec4` slots).
// Arrays of types are not necessarily tightly packed.
// An array of floats in such a block will not be the equivalent to an array of floats in C/C++. Arrays will only match their C/C++ definitions if the type is a multiple of 16 bytes.
// Ex: `float arr[N]` uses 16 bytes per element.
// Matrices
// Treated as arrays of vectors.
// They are column-major by default; you can change it with `layout(row_major)` or `layout(column_major)`.
// Struct
// The biggest struct member, rounded up to multiples of the size of `vec4` (behave like `vec4` slots).
// Struct members are effectively padded so that each member starts on a 16-byte boundary when necessary.
// The struct size will be the space needed by its members.
-
Examples :
layout(std140) uniform U { float a[3]; }; // size = 3 * 16 = 48 bytes
Base Alignment (std430)
-
Allowed usage :
-
SSBOs, Push Constants.
-
KHR_uniform_buffer_standard_layout.-
Core in Vulkan 1.2.
-
Allows the use of
std430memory layout in UBOs. -
These memory layout changes are only applied to
Uniforms.
-
-
-
Core in Vulkan 1.1; all Vulkan 1.1+ devices support relaxed block layout.
-
This extension allows implementations to indicate they can support more variation in block
Offsetdecorations. -
This comes up when using
std430memory layout where avec3(which is 12 bytes) is still defined as a 16 byte alignment. -
With relaxed block layout an application can fit a
floaton either side of thevec3and maintain the 16 byte alignment between them. -
Currently there is no way in GLSL to legally express relaxed block layout, but a developer can use the
--hlsl-offsetswithglslangto produce the desired offsets.
-
-
-
Relaxed layout used for shader-storage blocks and allows much tighter packing.
-
Requires newer GLSL 4.3+ or equivalent support.
// Scalars
float -> 4 bytes // for 32-bit IEEE-754
int -> 4 bytes // for 32-bit IEEE-754
uint -> 4 bytes // for 32-bit IEEE-754
bool -> 4 bytes // for 32-bit IEEE-754
// Vectors
// Base alignments
vec2 -> 8 bytes // 2 times the underlying scalar type.
vec3 -> 16 bytes // 4 times the underlying scalar type.
vec4 -> 16 bytes // 4 times the underlying scalar type.
// Arrays
// array stride is the natural alignment of the element.
// Ex: `float arr[N]` uses 4 bytes per element.
// Matrices
// Treated as arrays of vectors.
// They are column-major by default; you can change it with `layout(row_major)` or `layout(column_major)`.
// Struct
// Struct packing is tighter and follows natural alignments (less padding).
-
Examples :
layout(std430, binding=0) buffer B { float a[3]; }; // size = 3 * 4 = 12 bytes
Comparisons
-
Input Attributes vs Uniform Buffers :
-
"If you want a shader to access a resource that is not on vertex buffers, they must go through a descriptor set".
-
With Vertex Buffers we can pass arbitrary attributes to the vertex shader for each vertex.
-
Including global variables as vertex data would be a waste of memory, and it would require us to update the vertex buffer whenever the transformation changes.
-
The right way to tackle this in Vulkan is to use Resource Descriptors
-
-
Uniform Buffers vs Push Constants :
-
ChatGPT...
-
"Lets say I want to send the time, would it be optimal to send it as a ubo or a push constant? The time should not change between draw calls (it's irrelevant) in the same frame. Seems like a UBO I only need to set it once and every object would benefit from it, but a push constant needs to be send for every object?"
-
Exactly. For your “time” value, a Uniform Buffer is generally the more optimal choice in this scenario.
-
Push Constants
-
You must call
vkCmdPushConstantsfor each command buffer section where shaders need it. -
Since push constants are set per draw/dispatch scope, if you have many objects, you’d be redundantly re-sending the same value (time) multiple times in the same frame.
-
There’s no automatic “shared” state — every pipeline that uses it must get the value pushed explicitly.
-
-
Uniform Buffers
-
You can store the time in a uniform buffer once per frame, bind it once in a descriptor set, and then every draw call will see the same value without re-uploading.
-
Works well for “global” frame data (view/proj matrices, time, frame index, etc.).
-
Binding a pre-allocated UBO in a descriptor set has low overhead and avoids per-draw constant pushing.
-
-
Performance implication:
-
If the data is the same for all draws in a frame, a UBO avoids redundant driver calls and state changes, and makes it easier to keep the command buffer lean. Push constants are better suited for per-object or per-draw small data.
-
-
-
-
Storage Image vs. Storage Buffer :
-
While both storage images and storage buffers allow for read-write access in shaders, they have different use cases:
-
Storage Images :
-
Ideal for 2D or 3D data that benefits from texture operations like filtering or addressing modes.
-
-
Storage Buffers :
-
Better for arbitrary structured data or when you need to access data in a non-uniform pattern.
-
-
-
Texel Buffer vs. Storage Buffer :
-
Texel buffers and storage buffers also have different strengths:
-
Texel Buffers :
-
Provide texture-like access to buffer data, allowing for operations like filtering.
-
-
Storage Buffers :
-
More flexible for general-purpose data storage and manipulation.
-
-
-
Do
-
Do keep constant data small, where 128 bytes is a good rule of thumb.
-
Do use push constants if you do not want to set up a descriptor set/UBO system.
-
Do make constant data directly available in the shader if it is pre-determinable, such as with the use of specialization constants.
-
-
Avoid
-
Avoid indexing in the shader if possible, such as dynamically indexing into
bufferoruniformarrays, as this can disable shader optimisations in some platforms.
-
-
Impact
-
Failing to use the correct method of constant data will negatively impact performance, causing either reduced FPS and/or increased BW and load/store activity.
-
On Mali, register mapped uniforms are effectively free. Any spilling to buffers in memory will increase load/store cache accesses to the per thread uniform fetches.
-
Input Attributes
About
-
The only shader stage in core Vulkan that has an input attribute controlled by Vulkan is the vertex shader stage (
SHADER_STAGE_VERTEX).#version 450 layout(location = 0) in vec3 inPosition; void main() { gl_Position = vec4(inPosition, 1.0); } -
Other shader stages, such as a fragment shader stage, have input attributes, but the values are determined from the output of the previous stages run before it.
-
This involves declaring the interface slots when creating the
VkPipelineand then binding theVkBufferbefore draw time with the data to map. -
Before calling
vkCreateGraphicsPipelinesaVkPipelineVertexInputStateCreateInfostruct will need to be filled out with a list ofVkVertexInputAttributeDescriptionmappings to the shader.VkVertexInputAttributeDescription input = {}; input.location = 0; input.binding = 0; input.format = FORMAT_R32G32B32_SFLOAT; // maps to vec3 input.offset = 0; -
The only thing left to do is bind the vertex buffer and optional index buffer prior to the draw call.
vkBeginCommandBuffer(); // ... vkCmdBindVertexBuffer(); vkCmdDraw(); // ... vkCmdBindVertexBuffer(); vkCmdBindIndexBuffer(); vkCmdDrawIndexed(); // ... vkEndCommandBuffer(); -
Limits :
-
maxVertexInputAttributes -
maxVertexInputAttributeOffset
-
Memory Layout
-
 .
.
-
 .
.
-
 .
.
-
Single binding.
-
-
 .
.
-
One binding per attribute.
-
-
One binding or many bindings? It doesn't matter that much. In some cases one is better, etc, don't worry too much about it.
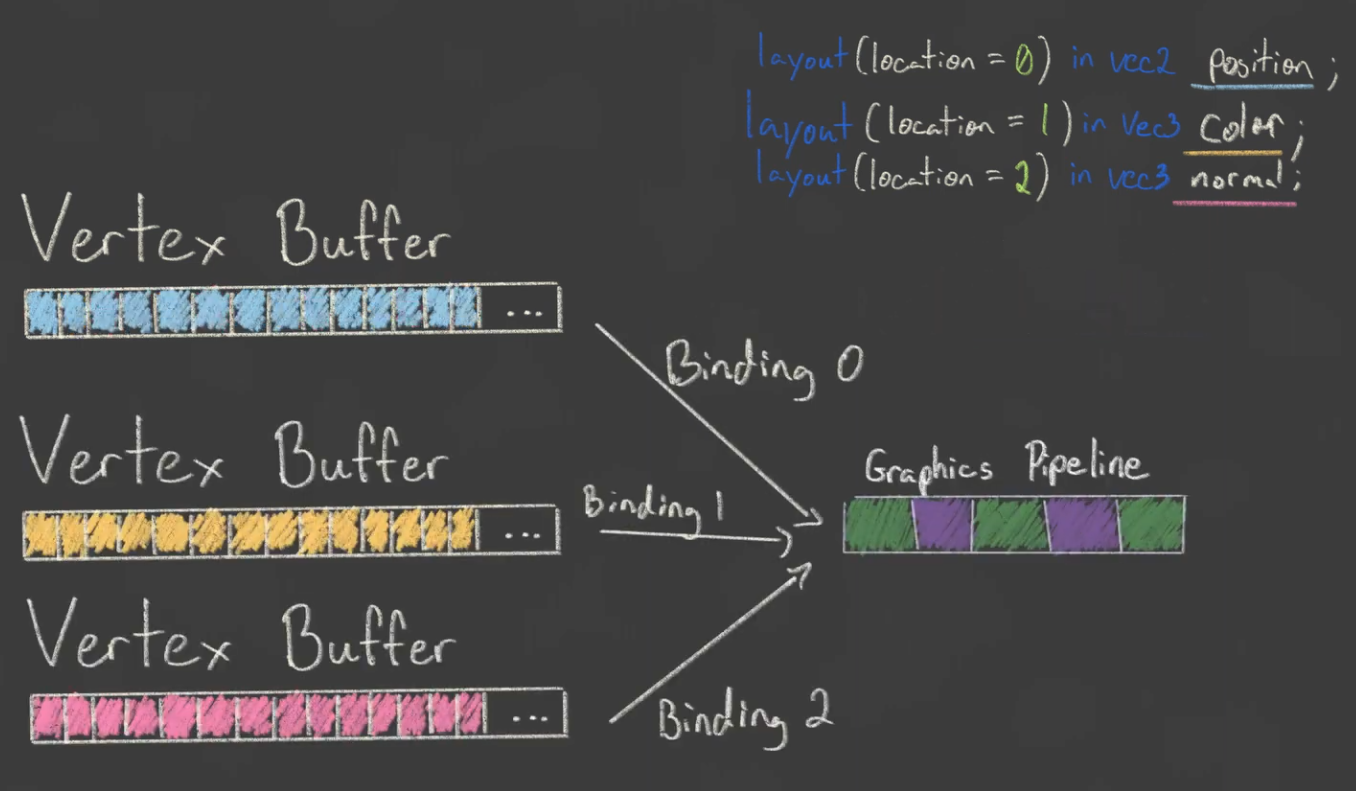
Vertex Input Binding / Vertex Buffer
-
Tell Vulkan how to pass this data format to the vertex shader once it's been uploaded into GPU memory
-
A vertex binding describes at which rate to load data from memory throughout the vertices.
-
It specifies the number of bytes between data entries and whether to move to the next data entry after each vertex or after each instance.
-
VkVertexInputBindingDescription.-
binding-
Specifies the index of the binding in the array of bindings.
-
-
stride-
Specifies the number of bytes from one entry to the next.
-
-
inputRate-
VERTEX_INPUT_RATE_VERTEX-
Move to the next data entry after each vertex.
-
-
VERTEX_INPUT_RATE_INSTANCE-
Move to the next data entry after each instance.
-
-
We're not going to use instanced rendering, so we'll stick to per-vertex data.
-
-
-
VkVertexInputAttributeDescription-
Describes how to handle vertex input.
-
An attribute description struct describes how to extract a vertex attribute from a chunk of vertex data originating from a binding description.
-
We have two attributes, position and color, so we need two attribute description structs.
-
binding-
Tells Vulkan from which binding the per-vertex data comes.
-
-
location-
References the
locationdirective of the input in the vertex shader.-
The input in the vertex shader with location
0is the position, which has two 32-bit float components.
-
-
-
format-
Describes the type of data for the attribute.
-
Implicitly defines the byte size of attribute data.
-
A bit confusingly, the formats are specified using the same enumeration as color formats.
-
The following shader types and formats are commonly used together:
-
float:FORMAT_R32_SFLOAT -
vec2:FORMAT_R32G32_SFLOAT -
vec3:FORMAT_R32G32B32_SFLOAT -
vec4:FORMAT_R32G32B32A32_SFLOAT
-
-
As you can see, you should use the format where the amount of color channels matches the number of components in the shader data type.
-
It is allowed to use more channels than the number of components in the shader, but they will be silently discarded.
-
If the number of channels is lower than the number of components, then the BGA components will use default values of
(0, 0, 1).
-
-
The color type (
SFLOAT,UINT,SINT) and bit width should also match the type of the shader input. See the following examples:-
ivec2:FORMAT_R32G32_SINT, a 2-component vector of 32-bit signed integers -
uvec4:FORMAT_R32G32B32A32_UINT, a 4-component vector of 32-bit unsigned integers -
double:FORMAT_R64_SFLOAT, a double-precision (64-bit) float
-
-
-
offset-
Specifies the number of bytes since the start of the per-vertex data to read from.
-
-
-
Graphics Pipeline Vertex Input Binding :
-
For the following vertices:
Vertex :: struct { pos: eng.Vec2, color: eng.Vec3, } vertices := [?]Vertex{ { { 0.0, -0.5 }, { 1.0, 0.0, 0.0 } }, { { 0.5, 0.5 }, { 0.0, 1.0, 0.0 } }, { { -0.5, 0.5 }, { 0.0, 0.0, 1.0 } }, } -
We setup this in the Graphics Pipeline creation:
vertex_binding_descriptor := vk.VertexInputBindingDescription{ binding = 0, stride = size_of(Vertex), inputRate = .VERTEX, } vertex_attribute_descriptor := [?]vk.VertexInputAttributeDescription{ { binding = 0, location = 0, format = .R32G32_SFLOAT, offset = cast(u32)offset_of(Vertex, pos), }, { binding = 0, location = 1, format = .R32G32B32_SFLOAT, offset = cast(u32)offset_of(Vertex, color), }, } vertex_input_create_info := vk.PipelineVertexInputStateCreateInfo { sType = .PIPELINE_VERTEX_INPUT_STATE_CREATE_INFO, vertexBindingDescriptionCount = 1, pVertexBindingDescriptions = &vertex_binding_descriptor, vertexAttributeDescriptionCount = len(vertex_attribute_descriptor), pVertexAttributeDescriptions = &vertex_attribute_descriptor[0], } -
The pipeline is now ready to accept vertex data in the format of the
verticescontainer and pass it on to our vertex shader.
-
-
Vertex Buffer :
-
If you run the program now with validation layers enabled, you'll see that it complains that there is no vertex buffer bound to the binding.
-
The next step is to create a vertex buffer and move the vertex data to it so the GPU is able to access it.
-
Creating :
-
Follow the tutorial for creating a buffer, specifying
BUFFER_USAGE_VERTEX_BUFFERas theBufferCreateInfousage.
-
-
Index Buffer
-
Motivation :
-
Drawing a rectangle takes two triangles, which means that we need a vertex buffer with six vertices. The problem is that the data of two vertices needs to be duplicated, resulting in redundancies.
-
The solution to this problem is to use an index buffer.
-
An index buffer is essentially an array of pointers into the vertex buffer.
-
It allows you to reorder the vertex data, and reuse existing data for multiple vertices.
-
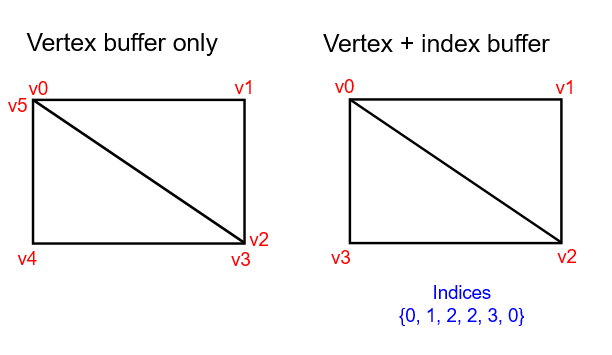 .
.
-
The first three indices define the upper-right triangle, and the last three indices define the vertices for the bottom-left triangle.
-
-
It is possible to use either
uint16_toruint32_tfor your index buffer depending on the number of entries invertices. We can stick touint16_tfor now because we’re using less than 65535 unique vertices. -
Just like the vertex data, the indices need to be uploaded into a
VkBufferfor the GPU to be able to access them.
-
-
Creating :
-
Follow the tutorial for creating a buffer, specifying
BUFFER_USAGE_INDEX_BUFFERas theBufferCreateInfousage.
-
-
Using :
-
We first need to bind the index buffer, just like we did for the vertex buffer.
-
The difference is that you can only have a single index buffer. It’s unfortunately not possible to use different indices for each vertex attribute, so we do still have to completely duplicate vertex data even if just one attribute varies.
-
An index buffer is bound with
vkCmdBindIndexBufferwhich has the index buffer, a byte offset into it, and the type of index data as parameters.-
As mentioned before, the possible types are
INDEX_TYPE_UINT16andINDEX_TYPE_UINT32.
-
-
Just binding an index buffer doesn’t change anything yet, we also need to change the drawing command to tell Vulkan to use the index buffer.
-
Remove the
vkCmdDrawline and replace it withvkCmdDrawIndexed.
-
Push Constants
-
A Push Constant is a small bank of values accessible in shaders.
-
These are designed for small amount (a few dwords) of high frequency data to be updated per-recording of the command buffer.
-
So that the shader can understand where this data will be sent, we specify a special push constants
<layout>in our shader code.
layout(push_constant) uniform MeshData {
mat4 model;
} mesh_data;
-
Choosing to use Push Constants :
-
In early implementations of Vulkan on Arm Mali, this was usually the fastest way of pushing data to your shaders. In more recent times, we have observed on Mali devices that overall they can be slower. If performance is something you are trying to maximise on Mali devices, descriptor sets may be the way to go. However, other devices may still favour push constants.
-
Having said this, descriptor sets are one of the more complex features of Vulkan, making the convenience of push constants still worth considering as a go-to method, especially if working with trivial data.
-
-
Limits :
-
maxPushConstantsSize-
guaranteed at least
128bytes on all devices. -
If you're using Vulkan 1.4 the minimum was increased to 256.
-
-
Offsets
-
 .
.
-
Ex1 :
layout(push_constant, std430) uniform pc { layout(offset = 32) vec4 data; }; layout(location = 0) out vec4 outColor; void main() { outColor = data; }VkPushConstantRange range = {}; range.stageFlags = SHADER_STAGE_FRAGMENT; range.offset = 32; range.size = 16;
Updating
-
Ex1 :
-
Push constants can be incrementally updated over the course of a command buffer.
// vkBeginCommandBuffer() vkCmdBindPipeline(); vkCmdPushConstants(offset: 0, size: 16, value = [0, 0, 0, 0]); vkCmdDraw(); // values = [0, 0, 0, 0] vkCmdPushConstants(offset: 4, size: 8, value = [1 ,1]); vkCmdDraw(); // values = [0, 1, 1, 0] vkCmdPushConstants(offset: 8, size: 8, value = [2, 2]); vkCmdDraw(); // values = [0, 1, 2, 2] // vkEndCommandBuffer()-
Interesting how old values are kept. Values that were not changed are preserved.
-
Lifetime
-
vkCmdPushConstantsis tied to theVkPipelineLayoutusage and therefore why they must match before a call to a command such asvkCmdDraw(). -
Because push constants are not tied to descriptors, the use of
vkCmdBindDescriptorSetshas no effect on the lifetime or pipeline layout compatibility of push constants. -
The same way it is possible to bind descriptor sets that are never used by the shader, the same is true for push constants.
CPU Performance
-
Push one struct once per draw instead of many separate vkCmdPushConstants calls (one call writing a small struct is far cheaper).
-
Many small state changes cause the driver to update internal tables, validate, or patch commands — that’s CPU work and cannot be avoided without batching.
-
Observations :
-
5 push calls were taking 7.65us. I groupped all them in 1 single push call, now taking 3.08us.
-
This was substancial, as at the time I was issuing this push calls hundreds of time per frame; I later reduced this number, but anyway, could be significant.
-
Descriptors Sets
About
-
VkDescriptorSet -
One Descriptor -> One Resource.
-
They are always organized in Descriptor Sets.
-
One or more descriptors contained.
-
Combine descriptors which are used in conjunction.
-
-
A handle or pointer into a resource.
-
Note that is not just a pointer, but a pointer + metadata.
-
-
A core mechanism used to bind resources to shaders.
-
Holds the binding information that connects shader inputs to data such as
VkBufferresources andVkImagetextures. -
Think of it as a set of GPU-side pointers that you bind once.
-
The internal representation of a descriptor set is whatever the driver wants it to be.
-
Content :
-
Where to find a Resource.
-
Usage type of a Resource.
-
Offsets, sometimes.
-
Some metadata, sometimes.
-
-
Example :
-
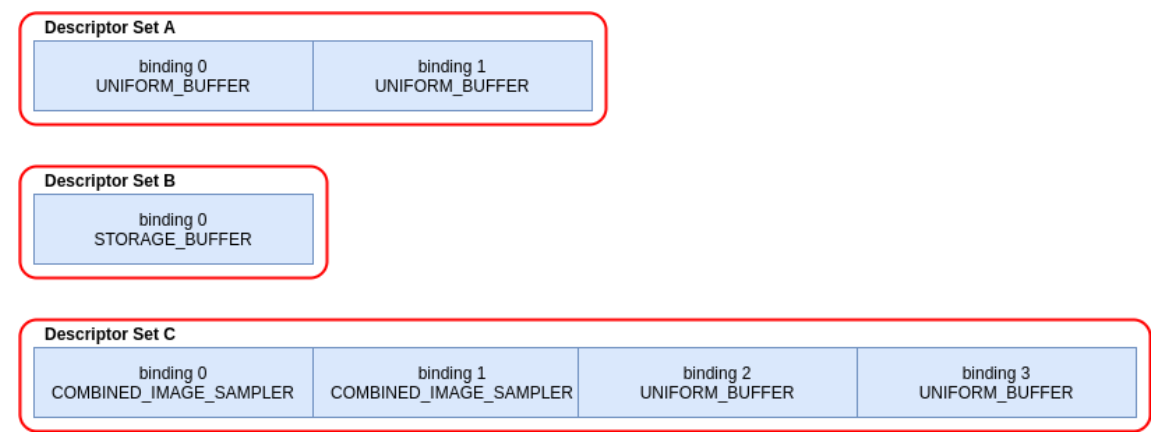 .
.
// Note - only set 0 and 2 are used in this shader layout(set = 0, binding = 0) uniform sampler2D myTextureSampler; layout(set = 0, binding = 2) uniform uniformBuffer0 { float someData; } ubo_0; layout(set = 0, binding = 3) uniform uniformBuffer1 { float moreData; } ubo_1; layout(set = 2, binding = 0) buffer storageBuffer { float myResults; } ssbo; -
-
API :
-
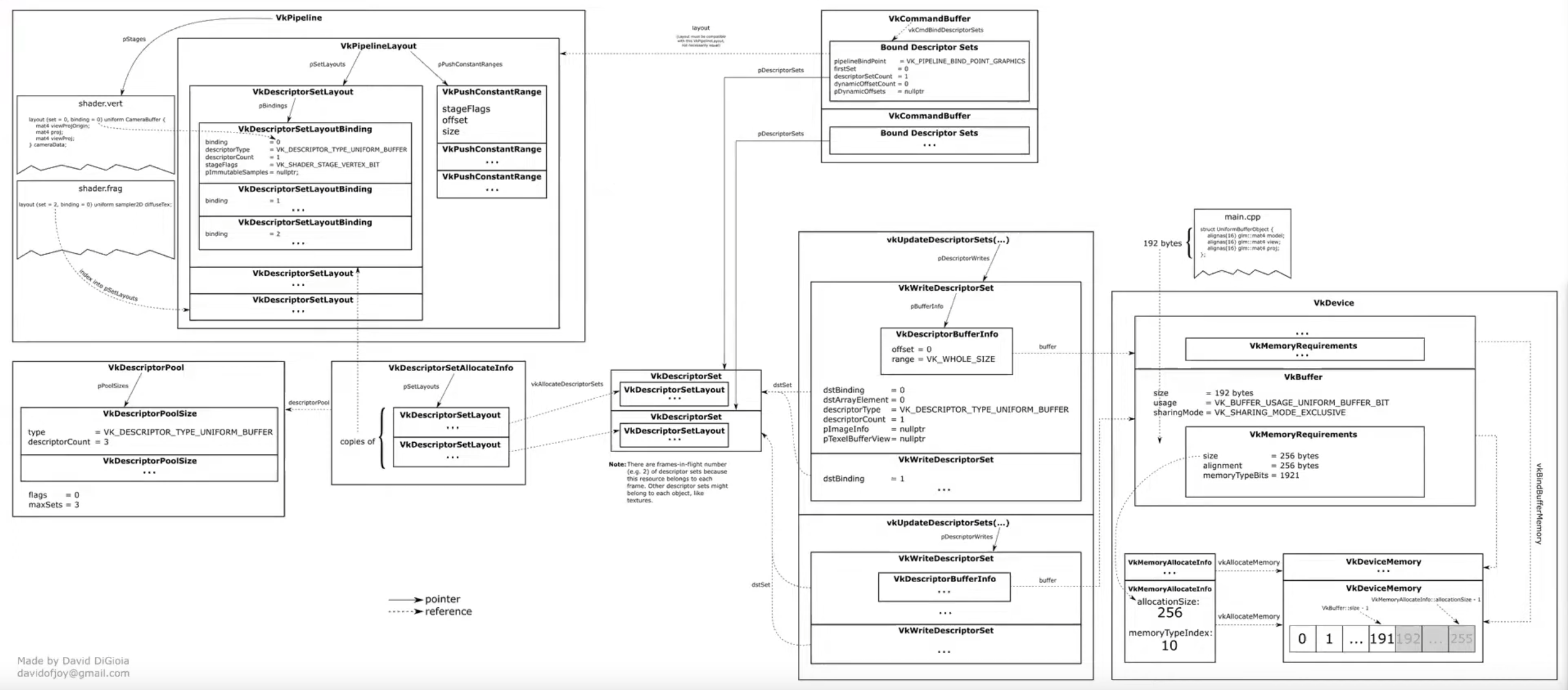 .
.
-
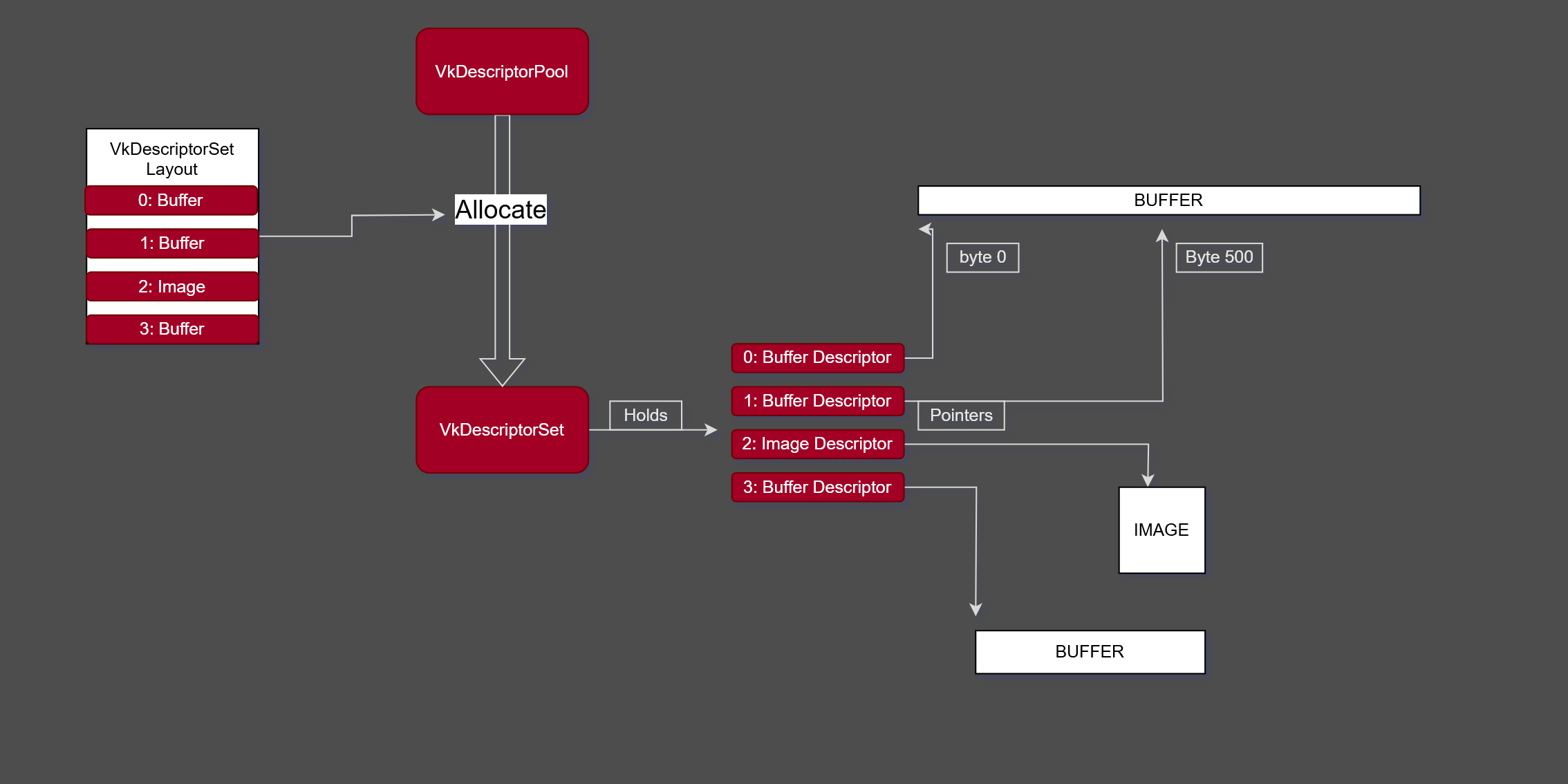 .
.
-
-
Limits :
-
maxBoundDescriptorSets -
Per stage limit
-
maxPerStageDescriptorSamplers -
maxPerStageDescriptorUniformBuffers -
maxPerStageDescriptorStorageBuffers -
maxPerStageDescriptorSampledImages -
maxPerStageDescriptorStorageImages -
maxPerStageDescriptorInputAttachments -
Per type limit
-
maxPerStageResources -
maxDescriptorSetSamplers -
maxDescriptorSetUniformBuffers -
maxDescriptorSetUniformBuffersDynamic -
maxDescriptorSetStorageBuffers -
maxDescriptorSetStorageBuffersDynamic -
maxDescriptorSetSampledImages -
maxDescriptorSetStorageImages -
maxDescriptorSetInputAttachments -
VkPhysicalDeviceDescriptorIndexingPropertiesif using Descriptor Indexing -
VkPhysicalDeviceInlineUniformBlockPropertiesEXTif using Inline Uniform Block
-
-
Visual explanation {0:00 -> 5:35} .
-
Nice.
-
The rest of the video is meh.
-
Difficulties
-
Problems :
-
"They are not bad but they very much force a specific rendering style: you have triple / quadrupled nested for loops, binding your things based on usage and then rebind descriptor sets as needed."
-
"Many of us are moving towards bindless rendering, where you just bind everything once in one big descriptor set, and then index into it at will; tho, Vulkan 1.0 does not greatly support, and also the descriptor count for it was quite low".
-
Cannot update descriptors after binding in a command buffer.
-
All descriptors must be valid, even if not used.
-
Descriptor arrays must be sampled uniformly.
-
Different invocations can’t use different indices.
-
Can sample “dynamically uniform”, e.g. runtime-based index.
-
-
Upper limit on descriptor counts.
-
Discourages GPU-driven rendering architectures.
-
Due to the need to set up descriptor sets per draw call it’s hard to adapt any of the aforementioned schemes to GPU-based culling or command submission.
-
-
-
Solutions :
-
Descriptor Indexing :
-
Available in 1.3, optional in 1.2, or
EXT_descriptor_indexing. -
Update descriptors after binding.
-
Update unused descriptors.
-
Relax requirement that all descriptors must be valid, even if unused.
-
Non-uniform array indexing.
-
-
Buffer Device Address :
-
Available in 1.3, optional in 1.2, or
KHR_buffer_device_address. -
Directly access buffers through addresses without a descriptor.
-
See [[#Physical Storage Buffer]] below.
-
-
Descriptor Buffers – EXT_descriptor_buffer :
-
Manage descriptors directly.
-
Similar to D3D12’s descriptor model.
-
-
Recommendations
-
Prefer a “bindless” design.
-
Use unbounded array descriptors pointing to big descriptor tables or sets with all known textures, buffers, and acceleration structures needed for the frame.
-
Upload as much data upfront as possible (textures, per-draw constants, and per-frame constants) and make them accessible through these descriptor arrays.
-
This design also makes it easier to implement ray tracing; that is, allowing access to every texture and buffers from each shader.
-
Cache descriptors on GPU-visible descriptor heaps (DirectX 12) or sets (Vulkan) with a known offset. This lowers the CPU overhead and virtually eliminates the need for copying descriptors.
-
Use multiple copies of the heap to handle descriptor changes gracefully, such as streaming textures and buffers. But don’t exceed the 1M and 2K limits. For more information, see the Not Recommended section later in this post.
-
Use root (DirectX 12) or push (Vulkan) constants. They are the fastest way to transfer per-draw varying constants.
-
Try to keep the number of descriptor sets in pipeline layouts as low as possible.
-
Use dynamic uniform and storage buffers for per-draw call changes.
-
Prefer using combined image and sampler descriptors.
-
Vulkan 1.2 enables passing device addresses of storage buffers as 64-bit values to shaders. This enables pointer-like workflows (such as casting) that are not available in DirectX or HLSL. GLSL exposes this through
GL_EXT_buffer_reference(2)and usesSPV_EXT_physical_storage_buffer. Try to make optimal usage of thebuffer_reference_aligninformation, as the hardware can leverage wider memory load operations accordingly. -
Do not have excessively sparse binding offsets in a single descriptor set.
-
Keep bindings as tightly packed as possible.
-
Unused binding indices waste memory and reduce cache efficiency.
-
-
Do not exceed 1M active descriptors and 2K samplers in total for the whole application (GPU-visible).
-
Otherwise, pipeline stalls across the whole GPU could occur when switching descriptor heaps (DirectX 12).
-
Whenever the limits are exceeded, it reduces the asynchronous execution efficiency of command lists.
-
On Vulkan, the deduplication of descriptors is automatically performed by the driver. The limits mentioned earlier only count towards unique variations.
-
In general, try to keep under the thresholds described in VkPhysicalDeviceLimits.
-
-
Avoid typed UAV loads or stores where possible.
Allocation
-
A scheme that works well is to use free lists of descriptor set pools; whenever you need a descriptor set pool, you allocate one from the free list and use it for subsequent descriptor set allocations in the current frame on the current thread. Once you run out of descriptor sets in the current pool, you allocate a new pool. Any pools that were used in a given frame need to be kept around; once the frame has finished rendering, as determined by the associated fence objects, the descriptor set pools can reset via
vkResetDescriptorPooland returned to free lists. While it’s possible to free individual descriptors from a pool viaDESCRIPTOR_POOL_CREATE_FREE_DESCRIPTOR_SET, this complicates the memory management on the driver side and is not recommended. -
When a descriptor set pool is created, application specifies the maximum number of descriptor sets allocated from it, as well as the maximum number of descriptors of each type that can be allocated from it. In Vulkan 1.1, the application doesn’t have to handle accounting for these limits – it can just call vkAllocateDescriptorSets and handle the error from that call by switching to a new descriptor set pool. Unfortunately, in Vulkan 1.0 without any extensions, it’s an error to call vkAllocateDescriptorSets if the pool does not have available space, so application must track the number of sets and descriptors of each type to know beforehand when to switch to a different pool.
-
Different pipeline objects may use different numbers of descriptors, which raises the question of pool configuration. A straightforward approach is to create all pools with the same configuration that uses the worst-case number of descriptors for each type – for example, if each set can use at most 16 texture and 8 buffer descriptors, one can allocate all pools with maxSets=1024, and pool sizes 16 1024 for texture descriptors and 8 1024 for buffer descriptors. This approach can work but in practice it can result in very significant memory waste for shaders with different descriptor count – you can’t allocate more than 1024 descriptor sets out of a pool with the aforementioned configuration, so if most of your pipeline objects use 4 textures, you’ll be wasting 75% of texture descriptor memory.
-
Strategies :
-
Two alternatives that provide a better balance memory use:
-
Measure an average number of descriptors used in a shader pipeline per type for a characteristic scene and allocate pool sizes accordingly. For example, if in a given scene we need 3000 descriptor sets, 13400 texture descriptors, and 1700 buffer descriptors, then the average number of descriptors per set is 4.47 textures (rounded up to 5) and 0.57 buffers (rounded up to 1), so a reasonable configuration of a pool is maxSets=1024, 5*1024 texture descriptors, 1024 buffer descriptors. When a pool is out of descriptors of a given type, we allocate a new one – so this scheme is guaranteed to work and should be reasonably efficient on average.
-
Group shader pipeline objects into size classes, approximating common patterns of descriptor use, and pick descriptor set pools using the appropriate size class. This is an extension of the scheme described above to more than one size class. For example, it’s typical to have large numbers of shadow/depth prepass draw calls, and large numbers of regular draw calls in a scene – but these two groups have different numbers of required descriptors, with shadow draw calls typically requiring 0 to 1 textures per set and 0 to 1 buffers when dynamic buffer offsets are used. To optimize memory use, it’s more appropriate to allocate descriptor set pools separately for shadow/depth and other draw calls. Similarly to general-purpose allocators that can have size classes that are optimal for a given application, this can still be managed in a lower-level descriptor set management layer as long as it’s configured with application specific descriptor set usages beforehand.
-
Implementation
-
Descriptors are like pointers, so as any pointer they need to allocate space to live ahead of time.
-
How many :
-
Its possible to have 1 very big descriptor pool that handles the entire engine, but that means we need to know what descriptors we will be using for everything ahead of time.
-
That can be very tricky to do at scale. Instead, we will keep it simpler, and we will have multiple descriptor pools for different parts of the project , and try to be more accurate with them.
-
I don't know what that actually means in practice.
-
-
-
-
Maintains a pool of descriptors, from which descriptor sets are allocated.
-
Descriptor pools are externally synchronized, meaning that the application must not allocate and/or free descriptor sets from the same pool in multiple threads simultaneously.
-
They are very opaque.
-
-
Contains a type of descriptor (same
VkDescriptorTypeas on the bindings above ), alongside a ratio to multiply themaxSetsparameter is. -
This lets us directly control how big the pool is going to be.
maxSetscontrols how manyVkDescriptorSetswe can create from the pool in total, and the pool sizes give how many individual bindings of a given type are owned. -
flags.-
Is a bitmask of VkDescriptorPoolCreateFlagBits specifying certain supported operations on the pool.
-
DESCRIPTOR_POOL_CREATE_FREE_DESCRIPTOR_SET-
Determines if individual descriptor sets can be freed or not:
-
We're not going to touch the descriptor set after creating it, so we don't need this flag. You can leave
flagsto its default value of0.
-
-
DESCRIPTOR_POOL_CREATE_UPDATE_AFTER_BIND-
Descriptor pool creation may fail with the error
ERROR_FRAGMENTATIONif the total number of descriptors across all pools (including this one) created with this bit set exceedsmaxUpdateAfterBindDescriptorsInAllPools, or if fragmentation of the underlying hardware resources occurs.
-
-
-
maxSets-
Is the maximum number of descriptor sets that can be allocated from the pool.
-
-
poolSizeCount-
Is the number of elements in
pPoolSizes.
-
-
pPoolSizes-
Is a pointer to an array of VkDescriptorPoolSize structures, each containing a descriptor type and number of descriptors of that type to be allocated in the pool.
-
If multiple
VkDescriptorPoolSizestructures containing the same descriptor type appear in thepPoolSizesarray then the pool will be created with enough storage for the total number of descriptors of each type. -
-
type-
Is the type of descriptor.
-
-
descriptorCount-
Is the number of descriptors of that type to allocate. If
typeisDESCRIPTOR_TYPE_INLINE_UNIFORM_BLOCKthendescriptorCountis the number of bytes to allocate for descriptors of this type.
-
-
-
-
-
-
-
descriptorPool-
Is the pool which the sets will be allocated from.
-
-
descriptorSetCount-
Determines the number of descriptor sets to be allocated from the pool.
-
-
pSetLayouts-
Is a pointer to an array of descriptor set layouts, with each member specifying how the corresponding descriptor set is allocated.
-
-
-
-
The allocated descriptor sets are returned in
pDescriptorSets. -
When a descriptor set is allocated, the initial state is largely uninitialized and all descriptors are undefined, with the exception that samplers with a non-null
pImmutableSamplersare initialized on allocation. -
Descriptors also become undefined if the underlying resource or view object is destroyed.
-
Descriptor sets containing undefined descriptors can still be bound and used, subject to the following conditions:
-
For descriptor set bindings created with the
PARTIALLY_BOUNDbit set:-
All descriptors in that binding that are dynamically used must have been populated before the descriptor set is consumed .
-
-
For descriptor set bindings created without the
PARTIALLY_BOUNDbit set:-
All descriptors in that binding that are statically used must have been populated before the descriptor set is consumed .
-
-
Descriptor bindings with descriptor type of
DESCRIPTOR_TYPE_INLINE_UNIFORM_BLOCKcan be undefined when the descriptor set is consumed ; though values in that block will be undefined. -
Entries that are not used by a pipeline can have undefined descriptors.
-
-
pAllocateInfo-
Is a pointer to a VkDescriptorSetAllocateInfo structure describing parameters of the allocation.
-
-
pDescriptorSets-
Is a pointer to an array of VkDescriptorSet handles in which the resulting descriptor set objects are returned.
-
-
-
Multithreading :
-
Descriptor pools are externally synchronized, meaning that the application must not allocate and/or free descriptor sets from the same pool in multiple threads simultaneously.
-
Command Pools are used to allocate, free, reset, and update descriptor sets. By creating multiple descriptor pools, each application host thread is able to manage a descriptor set in each descriptor pool at the same time.
-
Best Practices
-
Don’t allocate descriptor sets if nothing in the set changed. In the model with slots that are shared between different stages, this can mean that if no textures are set between two draw calls, you don’t need to allocate the descriptor set with texture descriptors.
-
Don't allocate descriptor sets from descriptor pools on performance critical code paths.
-
Don't allocate, free or update descriptor sets every frame, unless it is necessary.
-
Don't set
DESCRIPTOR_POOL_CREATE_FREE_DESCRIPTOR_SETif you do not need to free individual descriptor sets.-
Setting
DESCRIPTOR_POOL_CREATE_FREE_DESCRIPTOR_SETmay prevent the implementation from using a simpler (and faster) allocator.
-
Descriptor Types
Overview
-
For buffers, application must choose between uniform and storage buffers, and whether to use dynamic offsets or not. Uniform buffers have a limit on the maximum addressable size – on desktop hardware, you get up to 64 KB of data, however on mobile hardware some GPUs only provide 16 KB of data (which is also the guaranteed minimum by the specification). The buffer resource can be larger than that, but shader can only access this much data through one descriptor.
-
On some hardware, there is no difference in access speed between uniform and storage buffers, however for other hardware depending on the access pattern uniform buffers can be significantly faster. Prefer uniform buffers for small to medium sized data especially if the access pattern is fixed (e.g. for a buffer with material or scene constants). Storage buffers are more appropriate when you need large arrays of data that need to be larger than the uniform buffer limit and are indexed dynamically in the shader.
-
For textures, if filtering is required, there is a choice of combined image/sampler descriptor (where, like in OpenGL, descriptor specifies both the source of the texture data, and the filtering/addressing properties), separate image and sampler descriptors (which maps better to Direct3D 11 model), and image descriptor with an immutable sampler descriptor, where the sampler properties must be specified when pipeline object is created.
-
The relative performance of these methods is highly dependent on the usage pattern; however, in general immutable descriptors map better to the recommended usage model in other newer APIs like Direct3D 12, and give driver more freedom to optimize the shader. This does alter renderer design to a certain extent, making it necessary to implement certain dynamic portions of the sampler state, like per-texture LOD bias for texture fade-in during streaming, using shader ALU instructions.
Storage Images
-
DESCRIPTOR_TYPE_STORAGE_IMAGE -
Is a descriptor type that allows shaders to read from and write to an image without using a fixed-function graphics pipeline.
-
This is particularly useful for compute shaders and advanced rendering techniques.
// FORMAT_R32_UINT
layout(set = 0, binding = 0, r32ui) uniform uimage2D storageImage;
// example usage for reading and writing in GLSL
const uvec4 texel = imageLoad(storageImage, ivec2(0, 0));
imageStore(storageImage, ivec2(1, 1), texel);
-
Use cases :
-
Image Processing :
-
Storage images are ideal for image processing tasks like filters, blurs, and other post-processing effects.
-
-
Sampler
-
DESCRIPTOR_TYPE_SAMPLERandDESCRIPTOR_TYPE_SAMPLED_IMAGE.
layout(set = 0, binding = 0) uniform sampler samplerDescriptor;
layout(set = 0, binding = 1) uniform texture2D sampledImage;
// example usage of using texture() in GLSL
vec4 data = texture(sampler2D(sampledImage, samplerDescriptor), vec2(0.0, 0.0));
Combined Image Sampler
-
DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER -
On some implementations, it may be more efficient to sample from an image using a combination of sampler and sampled image that are stored together in the descriptor set in a combined descriptor.
layout(set = 0, binding = 0) uniform sampler2D combinedImageSampler;
// example usage of using texture() in GLSL
vec4 data = texture(combinedImageSampler, vec2(0.0, 0.0));
Uniform Buffer / UBO (Uniform Buffer Object)
-
DESCRIPTOR_TYPE_UNIFORM_BUFFER -
Uniform buffers can also have dynamic offsets at bind time (
DESCRIPTOR_TYPE_UNIFORM_BUFFER_DYNAMIC).
layout(set = 0, binding = 0) uniform uniformBuffer {
float a;
int b;
} ubo;
// example of reading from UBO in GLSL
int x = ubo.b + 1;
vec3 y = vec3(ubo.a);
-
Uniform Buffers commonly use
std140layout (strict alignment rules, predictable padding).-
Source: ChatGPT. I want to confirm.
-
/* UBO: small read-only data (std140) */
layout(set = 0, binding = 0, std140) uniform SceneParams {
mat4 viewProj;
vec4 lightPos;
float time;
} scene;
-
UBO (Uniform Buffer Object) :
-
“Uniform buffer object” is more of an OpenGL-era name, but some Vulkan tutorials and developers still use it informally to mean the same thing — the buffer that holds uniform data.
-
Storage Buffer / SSBO (Shader Storage Buffer Object)
-
SSBOs and UBOs.
-
Can I just put different data without restriction?
-
Yes. See the SSBO section for that.
-
-
SSBOs or UBOs?
-
Using storage buffers exclusively instead of uniform buffers can increase GPU time on some architectures.
-
I'll use SSBO, as that was the general recommendation.
-
Maybe I'll mix both.
-
-
-
Should I store an array of textures inside a layout(set = 0, binding = 1) uniform sampler2D texs[256]; or inside a SSBO? what are the differences?
-
Use sampler2D[] (descriptor arrays) for textures, not SSBOs. SSBOs are not designed to hold textures themselves.
-
You cannot store sampler2D or images inside an SSBO. Vulkan separates:
-
resources (images, samplers) → descriptors
-
data (numbers, structs) → buffers (SSBO/UBO)
-
-
-
DESCRIPTOR_TYPE_STORAGE_BUFFER -
GLSL uses distinct address spaces:
uniform→ UBO,buffer→ SSBO. -
Use
std430layout by default (tighter packing, fewer padding requirements). -
SSBO (Shader Storage Buffer Object) is a OpenGL term.
// Implicit std430 (default)
layout(set = 0, binding = 0) buffer storageBuffer {
float a;
int b;
} ssbo;
// Explicit std430
layout(set = 0, binding = 1, std430) buffer ParticleData {
vec4 pos[];
} particles;
// Reading and writing to a SSBO in GLSL
ssbo.a = ssbo.a + 1.0;
ssbo.b = ssbo.b + 1;
-
BufferBlockandUniformwould have been seen prior toKHR_storage_buffer_storage_class. -
Storage buffers can also have dynamic offsets at bind time
DESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMIC. -
Why SSBO for dynamic arrays :
-
std430allows tight packing and runtime-sized arrays(T data[]), which is ideal for dynamic-length storage. -
SSBOs allow arbitrary indexing, read/write, and atomics.
-
maxStorageBufferRange is usually much larger than
maxUniformBufferRange. -
You can use
*_DYNAMICdescriptors to bind multiple subranges of one large backing buffer cheaply.
-
-
Many arrays :
-
A buffer block may contain multiple arrays, but only the last member of the block may be a runtime-sized (unsized) array
T x[]. All other arrays must be fixed-size (compile-time constant) or you must implement sizing/offsets yourself.-
This is invalid , even with descriptor indexing:
layout(std430, set = 0, binding = 0) buffer FixedArrays { vec4 A[]; vec2 B[]; mat4 C[]; some_struct D[]; } fixedArrays; -
-
Use a
uint x[]:-
32-bit words; simplest and portable.
-
This is effectively an untyped byte/word blob stored in the SSBO and you manually reinterpret (cast) it in the shader
layout(std430, set = 0, binding = 0) buffer PackedBytes { uint countA; // number of A elements uint offsetA; // offset into data[] in uint words uint countB; uint offsetB; // offset into data[] in uint words uint countC; uint offsetC; uint data[]; // payload in 32-bit words } pb; // helpers float readFloat(uint baseWordIndex) { return uintBitsToFloat(pb.data[baseWordIndex]); } vec2 readVec2(uint baseWordIndex) { return vec2( uintBitsToFloat(pb.data[baseWordIndex + 0]), uintBitsToFloat(pb.data[baseWordIndex + 1]) ); } vec3 readVec3(uint baseWordIndex) { return vec3( uintBitsToFloat(pb.data[baseWordIndex + 0]), uintBitsToFloat(pb.data[baseWordIndex + 1]), uintBitsToFloat(pb.data[baseWordIndex + 2]) ); } vec4 readVec4(uint baseWordIndex) { return vec4( uintBitsToFloat(pb.data[baseWordIndex + 0]), uintBitsToFloat(pb.data[baseWordIndex + 1]), uintBitsToFloat(pb.data[baseWordIndex + 2]), uintBitsToFloat(pb.data[baseWordIndex + 3]) ); } mat4 readMat4(uint baseWordIndex) { // mat4 stored column-major as 16 floats (4 columns of vec4) return mat4( readVec4(baseWordIndex + 0), readVec4(baseWordIndex + 4), readVec4(baseWordIndex + 8), readVec4(baseWordIndex + 12) ); } -
-
Use a
vec4 x[]:-
128-bit blocks; simpler alignment for vec4/mat4 data.
// Pack everything into vec4 blocks for simple alignment layout(std430, set = 0, binding = 0) buffer Packed { uint countA; uint offsetA; // in vec4-blocks uint countB; uint offsetB; // in vec4-blocks uint countC; uint offsetC; // in vec4-blocks uint countD; uint offsetD; // in vec4-blocks vec4 blocks[]; // single runtime-sized array (last member) } packed; // helpers vec4 getA(uint i) { return packed.blocks[packed.offsetA + i]; } vec2 getB(uint i) { return packed.blocks[packed.offsetB + i].xy; // we store each B in one vec4 block } mat4 getC(uint i) { uint base = packed.offsetC + i * 4; // mat4 occupies 4 vec4 blocks return mat4(packed.blocks[base + 0], packed.blocks[base + 1], packed.blocks[base + 2], packed.blocks[base + 3]); } // for some_struct D that we store as 1 vec4 per element: some_struct getD(uint i) { vec4 v = packed.blocks[packed.offsetD + i]; // decode v -> some_struct fields } -
-
Use many SSBOs:
layout(std430, set=0, binding=0) buffer BufA { vec4 A[]; } bufA; layout(std430, set=0, binding=1) buffer BufB { vec2 B[]; } bufB; layout(std430, set=0, binding=2) buffer BufC { mat4 C[]; } bufC; layout(std430, set=0, binding=3) buffer BufD { some_struct D[]; } bufD;
-
Texel Buffer
-
Texel buffers are a way to access buffer data with texture-like operations in shaders.
-
-
The format specified in the shader (SPIR-V Image Format) must exactly match the format used when creating the VkImageView (Vulkan Format).
-
Require exact format matching between the shader and the view. The views must always match the shader exactly.
-
-
Uniform Texel Buffer :
-
DESCRIPTOR_TYPE_UNIFORM_TEXEL_BUFFER -
Read-only access.
layout(set = 0, binding = 0) uniform textureBuffer uniformTexelBuffer; // example of reading texel buffer in GLSL vec4 data = texelFetch(uniformTexelBuffer, 0);-
Use cases :
-
Lookup Tables :
-
Uniform texel buffers are useful for implementing lookup tables that need to be accessed with texture-like operations.
-
-
-
-
Storage Texel Buffer :
-
DESCRIPTOR_TYPE_STORAGE_TEXEL_BUFFER -
Read-write access.
// FORMAT_R8G8B8A8_UINT layout(set = 0, binding = 0, rgba8ui) uniform uimageBuffer storageTexelBuffer; // example of reading and writing texel buffer in GLSL int offset = int(gl_GlobalInvocationID.x); vec4 data = imageLoad(storageTexelBuffer, offset); imageStore(storageTexelBuffer, offset, uvec4(0));-
Use cases :
-
Particle Systems :
-
Storage texel buffers can be used to store and update particle data in a compute shader, which can then be read by a vertex shader for rendering.
-
-
-
Input Attachment
-
DESCRIPTOR_TYPE_INPUT_ATTACHMENT
layout (input_attachment_index = 0, set = 0, binding = 0) uniform subpassInput inputAttachment;
// example loading the attachment data in GLSL
vec4 data = subpassLoad(inputAttachment);
Updates
Implementation
-
A Descriptor Set, even though created and allocated, is still empty. We need to fill it up with data.
-
Updates must happen outside of a command record and execution.
-
No update after
vkCmdBindDescriptorSets(). -
Usually you update before
vkBeginCommandBuffer()or after thevkQueueSubmit()(if we know the sync is done for cmd).
-
-
If using Descriptor Indexing :
-
Descriptors can be updated after binding in command buffers.
-
Command buffer execution will use most recent updates.
-
-
 .
.
-
-
-
dstSet-
Is the destination descriptor set to update.
-
-
dstBinding-
Is the descriptor binding within that set.
-
-
dstArrayElement-
Remember that descriptors can be arrays, so we also need to specify the first index in the array that we want to update.
-
If not using an array, the index is simply
0. -
Is the starting element in that array.
-
If the descriptor binding identified by
dstSetanddstBindinghas a descriptor type ofDESCRIPTOR_TYPE_INLINE_UNIFORM_BLOCKthendstArrayElementspecifies the starting byte offset within the binding.
-
-
descriptorCount-
It's a descriptor count, not a descriptor SET count!!
-
Is the number of descriptors to update.
-
If the descriptor binding identified by
dstSetanddstBindinghas a descriptor type ofDESCRIPTOR_TYPE_INLINE_UNIFORM_BLOCK, thendescriptorCountspecifies the number of bytes to update. -
Otherwise,
descriptorCountis one of-
the number of elements in
pImageInfo -
the number of elements in
pBufferInfo -
the number of elements in
pTexelBufferView -
a value matching the
dataSizemember of a VkWriteDescriptorSetInlineUniformBlock structure in thepNextchain -
a value matching the
accelerationStructureCountof a VkWriteDescriptorSetAccelerationStructureKHR or VkWriteDescriptorSetAccelerationStructureNV structure in thepNextchain -
a value matching the
descriptorCountof a VkWriteDescriptorSetTensorARM structure in thepNextchain
-
-
-
descriptorType-
We need to specify the type of descriptor again
-
Is a VkDescriptorType specifying the type of each descriptor in
pImageInfo,pBufferInfo, orpTexelBufferView. -
It must be the same type as the
descriptorTypespecified inVkDescriptorSetLayoutBindingfordstSetatdstBinding, except ifVkDescriptorSetLayoutBindingfordstSetatdstBindingis equal toDESCRIPTOR_TYPE_MUTABLE_EXT. -
The type of the descriptor also controls which array the descriptors are taken from.
-
-
pBufferInfo-
Is a pointer to an array of VkDescriptorBufferInfo structures or is ignored, as described below.
-
-
Structure specifying descriptor buffer information
-
Specifies the buffer and the region within it that contains the data for the descriptor.
-
buffer-
Is the buffer resource or NULL_HANDLE .
-
-
offset-
Is the offset in bytes from the start of
buffer. -
Access to buffer memory via this descriptor uses addressing that is relative to this starting offset.
-
For
DESCRIPTOR_TYPE_UNIFORM_BUFFER_DYNAMICandDESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMICdescriptor types:-
offsetis the base offset from which the dynamic offset is applied.
-
-
-
range-
Is the size in bytes that is used for this descriptor update, or
WHOLE_SIZEto use the range fromoffsetto the end of the buffer.-
When
rangeisWHOLE_SIZEthe effective range is calculated at vkUpdateDescriptorSets by taking the size ofbufferminus theoffset.
-
-
For
DESCRIPTOR_TYPE_UNIFORM_BUFFER_DYNAMICandDESCRIPTOR_TYPE_STORAGE_BUFFER_DYNAMICdescriptor types:-
rangeis the static size used for all dynamic offsets.
-
-
-
-
-
pImageInfo-
Is a pointer to an array of VkDescriptorImageInfo structures or is ignored, as described below.
-
-
imageLayout-
Is the layout that the image subresources accessible from
imageViewwill be in at the time this descriptor is accessed. -
Is used in descriptor updates for types
DESCRIPTOR_TYPE_SAMPLED_IMAGE,DESCRIPTOR_TYPE_STORAGE_IMAGE,DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER, andDESCRIPTOR_TYPE_INPUT_ATTACHMENT.
-
-
imageView-
Is an image view handle or NULL_HANDLE .
-
Is used in descriptor updates for types
DESCRIPTOR_TYPE_SAMPLED_IMAGE,DESCRIPTOR_TYPE_STORAGE_IMAGE,DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER, andDESCRIPTOR_TYPE_INPUT_ATTACHMENT.
-
-
sampler-
Is a sampler handle.
-
Is used in descriptor updates for types
DESCRIPTOR_TYPE_SAMPLERandDESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLERif the binding being updated does not use immutable samplers.
-
-
-
-
pTexelBufferView-
Is a pointer to an array of VkBufferView handles as described in the Buffer Views section or is ignored, as described below.
-
-
-
-
descriptorWriteCount-
Is the number of elements in the
pDescriptorWritesarray.
-
-
pDescriptorWrites-
Is a pointer to an array of VkWriteDescriptorSet structures describing the descriptor sets to write to.
-
-
descriptorCopyCount-
Is the number of elements in the
pDescriptorCopiesarray.
-
-
pDescriptorCopies-
Is a pointer to an array of VkCopyDescriptorSet structures describing the descriptor sets to copy between.
-
-
Best Practices
-
Don’t update descriptor sets if nothing in the set changed. In the model with slots that are shared between different stages, this can mean that if no textures are set between two draw calls, you don’t need to update the descriptor set with texture descriptors.
-
When rendering dynamic objects the application will need to push some amount of per-object data to the GPU, such as the MVP matrix. This data may not fit into the push constant limit for the device, so it becomes necessary to send it to the GPU by putting it into a
VkBufferand binding a descriptor set that points to it. -
Materials also need their own descriptor sets, which point to the textures they use. We can either bind per-material and per-object descriptor sets separately or collate them into a single set. Either way, complex applications will have a large amount of descriptor sets that may need to change on the fly, for example due to textures being streamed in or out.
-
Not-good Solution: One or more pools per-frame, resetting the pool :
-
The simplest approach to circumvent the issue is to have one or more
VkDescriptorPools per frame, reset them at the beginning of the frame and allocate the required descriptor sets from it. This approach will consist of a vkResetDescriptorPool() call at the beginning, followed by a series of vkAllocateDescriptorSets() and vkUpdateDescriptorSets() to fill them with data. -
This is very useful for things like per-frame descriptors. That way we can have descriptors that are used just for one frame, allocated dynamically, and then before we start the frame we completely delete all of them in one go.
-
This is confirmed to be a fast path by GPU vendors, and recommended to use when you need to handle per-frame descriptor sets.
-
The issue is that these calls can add a significant overhead to the CPU frame time, especially on mobile. In the worst cases, for example calling vkUpdateDescriptorSets() for each draw call, the time it takes to update descriptors can be longer than the time of the draws themselves.
-
-
Solution: Caching descriptor sets :
-
A major way to reduce descriptor set updates is to re-use them as much as possible. Instead of calling vkResetDescriptorPool() every frame, the app will keep the
VkDescriptorSethandles stored with some caching mechanism to access them. -
The cache could be a hashmap with the contents of the descriptor set (images, buffers) as key. This approach is used in our framework by default. It is possible to remove another level of indirection by storing descriptor set handles directly in the materials and/or meshes.
-
Caching descriptor sets has a dramatic effect on frame time for our CPU-heavy scene.
-
In this game on a 2019 mobile phone it went from 44ms (23fps) to 27ms (37fps). This is a 38% decrease in frame time.
-
This system is reasonably easy to implement for a static scene, but it becomes harder when you need to delete descriptor sets. Complex engines may implement techniques to figure out which descriptor sets have not been accessed for a certain number of frames, so they can be removed from the map.
-
This may correspond to calling vkFreeDescriptorSets() , but this solution poses another issue: in order to free individual descriptor sets the pool has to be created with the
DESCRIPTOR_POOL_CREATE_FREE_DESCRIPTOR_SETflag. Mobile implementations may use a simpler allocator if that flag is not set, relying on the fact that pool memory will only be recycled in block. -
It is possible to avoid using that flag by updating descriptor sets instead of deleting them. The application can keep track of recycled descriptor sets and re-use one of them when a new one is requested.
-
-
Solution: One buffer per-frame :
-
We will now explore an alternative approach, that is complementary to descriptor caching in some way. Especially for applications in which descriptor caching is not quite feasible, buffer management is another lever for optimizing performance.
-
As discussed at the beginning, each rendered object will typically need some uniform data along with it, that needs to be pushed to the GPU somehow. A straightforward approach is to store a
VkBufferper object and update that data for each frame. -
This already poses an interesting question: is one buffer enough? The problem is that this data will change dynamically and will be in use by the GPU while the frame is in flight.
-
Since we do not want to flush the GPU pipeline between each frame, we will need to keep several copies of each buffer, one for each frame in flight.
-
Another similar option is to use just one buffer per object, but with a size equal to
num_frames * buffer_size, then offset it dynamically based on the frame index.-
For each frame, one buffer per object is created and filled with data. This means that we will have many descriptor sets to create, since every object will need one that points to its
VkBuffer. Furthermore, we will have to update many buffers separately, meaning we cannot control their memory layout and we might lose some optimization opportunities with caching.
-
-
We can address both problems by reverting the approach: instead of having a
VkBufferper object containing per-frame data, we will have aVkBufferper frame containing per-object data. The buffer will be cleared at the beginning of the frame, then each object will record its data and will receive a dynamic offset to be used at vkCmdBindDescriptorSets() time. -
With this approach we will need fewer descriptor sets, as more objects can share the same one: they will all reference the same
VkBuffer, but at different dynamic offsets. Furthermore, we can control the memory layout within the buffer. -
Using a single large
VkBufferin this case shows a performance improvement similar to descriptor set caching. -
For this relatively simple scene stacking the two approaches does not provide a further performance boost, but for a more complex case they do stack nicely:
-
Descriptor caching is necessary when the number of descriptor sets is not just due to
VkBuffers with uniform data, for example if the scene uses a large amount of materials/textures. -
Buffer management will help reduce the overall number of descriptor sets, thus cache pressure will be reduced and the cache itself will be smaller.
-
-
(2025-09-08)
-
I personally liked this technique much more than descriptor caching.
-
It sounds more concrete than fiddling with descriptor sets.
-
Reminds me of Buffer Device Address.
-
-
-
Do
-
Update already allocated but no longer referenced descriptor sets, instead of resetting descriptor pools and reallocating new descriptor sets.
-
Prefer reusing already allocated descriptor sets, and not updating them with the same information every time.
-
Consider caching your descriptor sets when feasible.
-
Consider using a single (or few)
VkBufferper frame with dynamic offsets. -
Batch calls to vkAllocateDescriptorSets if possible – on some drivers, each call has measurable overhead, so if you need to update multiple sets, allocating both in one call can be faster;
-
To update descriptor sets, either use vkUpdateDescriptorSets with descriptor write array, or use
vkUpdateDescriptorSetWithTemplatefrom Vulkan 1.1. Using the descriptor copy functionality ofvkUpdateDescriptorSetsis tempting with dynamic descriptor management for copying most descriptors out of a previously allocated array, but this can be slow on drivers that allocate descriptors out of write-combined memory. Descriptor templates can reduce the amount of work application needs to do to perform updates – since in this scheme you need to read descriptor information out of shadow state maintained by application, descriptor templates allow you to tell the driver the layout of your shadow state, making updates substantially faster on some drivers. -
Prefer dynamic uniform buffers to updating uniform buffer descriptors. Dynamic uniform buffers allow to specify offsets into buffer objects using pDynamicOffsets argument of vkCmdBindDescriptorSets without allocating and updating new descriptors. This works well with dynamic constant management where constants for draw calls are allocated out of large uniform buffers, substantially reduce CPU overhead, and can be more efficient on GPU. While on some GPUs the number of dynamic buffers must be kept small to avoid extra overhead in the driver, one or two dynamic uniform buffers should work well in this scheme on all architectures.
-
On some drivers, unfortunately the allocate & update path is not very optimal – on some mobile hardware, it may make sense to cache descriptor sets based on the descriptors they contain if they can be reused later in the frame.
-
Descriptor Set Layout
-
Contains the information about what that descriptor set holds.
-
Specifies the types of resources that are going to be accessed by the pipeline, just like a render pass specifies the types of attachments that will be accessed.
-
How many :
-
You need to specify a descriptor set layout for each descriptor set when creating the pipeline layout.
-
You can use this feature to put descriptors that vary per-object and descriptors that are shared into separate descriptor sets.
-
In that case, you avoid rebinding most of the descriptors across draw calls which are potentially more efficient.
-
-
Since the buffer structure is identical across frames, one layout suffices.
-
Create only 1 descriptor set layout, regardless of frames in-flight.
-
This layout defines the type of resource (e.g.,
VKDESCRIPTORTYPEUNIFORMBUFFER) and its binding point.
-
-
-
-
Opaque handle to a descriptor set layout object.
-
Is defined by an array of zero or more descriptor bindings.
-
Where it's used :
-
VkDescriptorSetLayoutBinding.-
Structure specifying a descriptor set layout binding.
-
Each individual descriptor binding is specified by a descriptor type, a count (array size) of the number of descriptors in the binding, a set of shader stages that can access the binding, and (if using immutable samplers) an array of sampler descriptors.
-
Bindings that are not specified have a
descriptorCountandstageFlagsof zero, and the value ofdescriptorTypeis undefined. -
binding-
Is the binding number of this entry and corresponds to a resource of the same binding number in the shader stages.
-
Used in the shader and the type of descriptor, which is a uniform buffer object.
-
-
descriptorType-
Is a VkDescriptorType specifying which type of resource descriptors are used for this binding.
-
-
descriptorCount-
Insight :
-
It's a descriptor count, not a descriptor SET count !! It's just to specify how many resources is expected to be in that binding.
-
It makes complete sense to be used for arrays.
-
Caio:
-
What happens if the values don't match? For example, trying to get the index 5 of the array, when the binding was described having
descriptorCount = 1?
-
-
Oni:
-
I don't know if this is specified. I guess it's only going to update the first element. So you're going to read bogus data. Maybe it changes between different drivers, no idea.
-
-
-
What value to use :
-
A MVP transformation is in a single uniform buffer, so we using a
descriptorCountof1. -
In other words, a whole struct counts as
1.
-
-
Is the number of descriptors contained in the binding, accessed in a shader as an array.
-
Except if
descriptorTypeisDESCRIPTOR_TYPE_INLINE_UNIFORM_BLOCKin which casedescriptorCountis the size in bytes of the inline uniform block.
-
-
If
descriptorCountis zero this binding entry is reserved and the resource must not be accessed from any stage via this binding within any pipeline using the set layout. -
It is possible for the shader variable to represent an array of uniform buffer objects, and this property specifies the number of values in the array.
-
Examples :
-
This could be used to specify a transformation for each of the bones in a skeleton for skeletal animation.
-
-
-
stageFlags-
Is a bitmask of VkShaderStageFlagBits specifying which pipeline shader stages can access a resource for this binding.
-
SHADER_STAGE_ALLis a shorthand specifying all defined shader stages, including any additional stages defined by extensions.
-
-
If a shader stage is not included in
stageFlags, then a resource must not be accessed from that stage via this binding within any pipeline using the set layout. -
Other than input attachments which are limited to the fragment shader, there are no limitations on what combinations of stages can use a descriptor binding, and in particular a binding can be used by both graphics stages and the compute stage.
-
-
pImmutableSamplers-
Affects initialization of samplers.
-
If
descriptorTypespecifies aDESCRIPTOR_TYPE_SAMPLERorDESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLERtype descriptor, thenpImmutableSamplerscan be used to initialize a set of immutable samplers . -
If
descriptorTypeis not one of these descriptor types, thenpImmutableSamplersis ignored . -
Immutable samplers are permanently bound into the set layout and must not be changed; updating a
DESCRIPTOR_TYPE_SAMPLERdescriptor with immutable samplers is not allowed and updates to aDESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLERdescriptor with immutable samplers does not modify the samplers (the image views are updated, but the sampler updates are ignored). -
If
pImmutableSamplersis notNULL, then it is a pointer to an array of sampler handles that will be copied into the set layout and used for the corresponding binding. Only the sampler handles are copied; the sampler objects must not be destroyed before the final use of the set layout and any descriptor pools and sets created using it. -
If
pImmutableSamplersisNULL, then the sampler slots are dynamic and sampler handles must be bound into descriptor sets using this layout. ]
-
-
-
VkDescriptorSetLayoutCreateInfo.-
pBindings-
A pointer to an array of
VkDescriptorSetLayoutBindingstructures.
-
-
bindingCount-
Is the number of elements in
pBindings.
-
-
flags-
Is a bitmask of VkDescriptorSetLayoutCreateFlagBits specifying options for descriptor set layout creation.
-
-
-
vkCreateDescriptorSetLayout().-
Create a new descriptor set layout.
-
pCreateInfo-
Is a pointer to a VkDescriptorSetLayoutCreateInfo structure specifying the state of the descriptor set layout object.
-
-
pAllocator-
Controls host memory allocation as described in the Memory Allocation chapter.
-
-
pSetLayout-
Is a pointer to a VkDescriptorSetLayout handle in which the resulting descriptor set layout object is returned.
-
-
-
-
-
Structure specifying the parameters of a newly created pipeline layout object
-
setLayoutCount-
Is the number of descriptor sets included in the pipeline layout.
-
How it works :
-
It's possible to have multiple descriptor sets (
set = 0,set = 1, etc). -
"You can have set = 0 being a set that is always bound and never changes, set = 1 is something specific to the current object being rendered, etc."
-
-
-
pSetLayouts-
Is a pointer to an array of
VkDescriptorSetLayoutobjects. -
The implementation must not access these objects outside of the duration of the command this structure is passed to.
-
-
Binding
-
A Descriptor state is tracked only inside a command buffer; they are always bound at command buffer level; their state is local to command buffers.
-
They are not bound at queue level or global level, only to command buffers.
-
-
 .
.
-
Which set index to choose :
-
According to GPU vendors, each descriptor set slot has a cost, so the fewer we have, the better.
-
"Organize shader inputs into "sets" by update frequency."
-
Rarely changes -> low index.
-
Changes frequently -> high index.
-
Usually Descriptor Set 0 is used to always bind some global scene data, which will contain some uniform buffers and some special textures, and Descriptor Set 1 will be used for per-object data.
-
-
-
It needs to be done before the
vkCmdDrawIndexed()calls, for example. -
commandBuffer-
Is the command buffer that the descriptor sets will be bound to.
-
-
pipelineBindPoint-
Is a VkPipelineBindPoint indicating the type of the pipeline that will use the descriptors. There is a separate set of bind points for each pipeline type, so binding one does not disturb the others.
-
Unlike vertex and index buffers, descriptor sets are not unique to graphics pipelines, therefore, we need to specify if we want to bind descriptor sets to the graphics or compute pipeline.
-
Indicates the type of the pipeline that will use the descriptor.
-
There is a separate set of bind points for each pipeline type, so binding one does not disturb the others.
-
 .
.
-
A raytracing command takes the currently bound descriptors from the raytracing bind point.
-
A draw command takes the currently bound descriptors from the graphics bind point.
-
The two don't interfere with each other.
-
-
-
layout-
Is a VkPipelineLayout object used to program the bindings.
-
-
firstSet-
Is the set number of the first descriptor set to be bound.
-
-
descriptorSetCount-
Is the number of elements in the
pDescriptorSetsarray.
-
-
pDescriptorSets-
Is a pointer to an array of handles to VkDescriptorSet objects describing the descriptor sets to bind to.
-
-
dynamicOffsetCount-
Is the number of dynamic offsets in the
pDynamicOffsetsarray.
-
-
pDynamicOffsets-
Is a pointer to an array of
uint32_tvalues specifying dynamic offsets.
-
-
Strategy: Descriptor Indexing (
EXT_descriptor_indexing
)
Plan
-
In non-indirect, the drawing can be made by
rd.sprite_draw(cmd, &world.bg_neve), but with indirect, the call will be something likerd.sprites_draw(cmd, { sprite1, sprite2... }); the data will no longer be passed as push constants, the only useful data is the instance index. A[]Draw_Datawill be used inside the shader, using the instance index for that, getting the information of the other indices. -
Check 'Vulkan.md -> Render Loop -> Drawing Commands -> Draw Indirect'.
-
Profiling :
-
With
window_render_queue_recordingon repeat, I get ~100fps; with it off, I get ~500fps.-
Seems that the lag is just from the CPU.
-
-
No Y-Sort is being done. Total of 434 draws inside the layers.
-
I'm CPU bound, for sure.
-
-
Globals :
-
Camera view/proj, lights, ambient, etc.
-
I could just bind this once as well.
-
-
Material Data :
-
The Material index is used to look up material data from material storage buffer. The textures can then be accessed using the indices from the material data and the descriptor array.
-
I'd use the instance index (or similar) to index into a
[]Material_Data.
-
-
Model Matrix / Transforms :
-
Same as material data. I can send via push constants if direct drawing, or via
[]model_matrixif indirect drawing.
-
-
Draw Data :
-
Indices to index into the other arrays.
struct DrawData { uint materialIndex; uint transformOffset; uint vertexOffset; uint unused0; // vec4 padding // ... extra gameplay data };-
Vertex Shader:
DrawData dd = drawData[gl_DrawIDARB]; TransformData td = transformData[dd.transformOffset]; vec4 positionLocal = vec4(positionData[gl_VertexIndex + dd.vertexOffset], 1.0); vec3 positionWorld = mat4x3(td.transform[0], td.transform[1], td.transform[2]) * positionLocal; -
Frag Shader:
DrawData dd = drawData[drawId]; MaterialData md = materialData[dd.materialIndex]; vec4 albedo = texture(sampler2D(materialTextures[md.albedoTexture], albedoSampler), uv * vec2(md.tilingX, md.tilingY));
-
-
Overall :
-
[]textures -
[]material_data-
uv, flip, modulate, etc.
-
-
[]model_matrices-
transforms.
-
-
[]draw_data-
Indices to index into the other arrays.
-
-
vertex/indices
-
As input attributes with Indirect Drawing, to then use Bindless.
-
-
-
Slots :
-
tex buffer and material data buffer will be in the same set 0, or should they be 0/1?
-
Probably every bind is on desc set 0
-
The slots are based on frequency, but every single binding I'm talking about might just be bound once globally without problems
-
-
Vertex :
-
Indirect vs Full bindless:
-
I'll use Indirect Drawing for now. ChatGPU deep search didn't give me much.
-
-
Go for bindless first with drawing direct. Instead of using the
instanceIDor similar, I just send the draw_data index via push constants. this way, the shader will be completely finalized, but then I batch the draws via draw indirect and use theinstanceIDinstead of the push constants ID-
What not invert and do indirect first? I cannot do that, as the
instanceIDis useless without a bindless design! I NEED to have use for the ID, as I cannot bind desc sets or push constants for each individual draw! bindless first is a MUST.
-
-
Having to bind vertex buffers per-draw would not work for a fully bindless design.
-
Indirect Drawing:
-
Full bindless:
-
Using a large index buffer: We need to bind index data. If just like the vertex data, index data is allocated in one large index buffer, we only need to bind it once using
vkCmdBindIndexBuffer. -
Some hardware doesn’t support vertex buffers as a first-class entity, and the driver has to emulate vertex buffer binding, which causes some CPU-side slowdowns when using
vkCmdBindVertexBuffers. -
In a fully bindless design, we need to assume that all vertex buffers are suballocated in one large buffer and either use per-draw vertex offsets (
vertexOffsetargument tovkCmdDrawIndexed) to have hardware fetch data from it, or pass an offset in this buffer to the shader with each draw call and fetch data from the buffer in the shader. Both approaches can work well, and might be more or less efficient depending on the GPU.
-
-
Mesh Shaders.
-
Mesh Shaders is probably what is most true to the bindless strategy, but I won't go that way yet (too soon, too new).
-
-
Compute-
Maybe I could use a compute to do this for me, but then I'd lose the rasterizer.
-
-
Design :
-
I want the resources to be able to change. Easy access to modification. This is not just blind flexibility, but a way to make working with shaders easier.
-
-
-
For textures :
-
To change the desc set, I have to change the textures. I need a reference to it. It's a relation between desc set and image (resource).
-
The problem with the resource holding the index, is that only 1 desc set can be used per resource; the same texture can no longer belong to different desc sets.
-
If a desc set with globals is bound, one graphics pipeline might use it differently then the composite pipeline, for example.-
-
-
The sprite stores a stable handle to the texture, where the texture is stored inside a "stable array":
-
Storing the texture inside a sparse_set:
-
Done, as part of the ECS design.
-
-
Storing the texture inside a handle_map:-
Each "thing" inside a
handle_maphas to be a struct containing a.handleentry; the type of handle from the "thing" and the type of handle used to create thehandle_mapmust match.-
"I have a card to a list of things. This card will give me a result that can or not be nil. If the result is not nil, a check is made so the internals of the result match what it was expected from the handle; this avoids a handle giving a old result".
-
This "identity check" could be made without having to change the "thing" to hold the handle as well; avoiding
.handleinside the stored data.-
Why would I do that? I don't like how the process of using a handle, which should just basically be a "safe pointer and index to an array" has to change the data struct itself it is storing.
-
-
-
-
I don't love this solution, as it's not even that cache efficient.
-
-
-
The sprite stores a pointer to the texture, where the texture is stored inside an array:-
This pointer is not stable, as removing a texture from the array makes every other pointer to the array to be incorrect.
-
-
The sprite stores the texture itself:-
It's a copy, and a bad one.
-
-
The desc set stores the.texture_idx, where the texture is stored in a separate container-
No actual reason to do that.
-
It could make sense that the desc set keep track of bound things, but it doesn't make sense that the sprite wouldn't store the information about what the sprite is using.
-
In this context, the sprite is either OOP, storing the information inside itself, or it's DOD, by using the sprite itself as handle and accessing a texture container using this handle.
-
-
-
The sprite stores the:texture_idx-
The sprite would store the information about how a texture and a desc set relate.
-
This can be a bit odd. If the desc set is updated, or a texture change, the sprite is the last to know, and it may not know.
-
This is a consequence of not storing a reference to something, but a concrete data, while the sprite doesn't own that data. It's a copy of something that the sprite has no agency over.
-
-
-
-
For transforms :
-
I don't like how there's duplicate information. The sprite owns the transform information, but now it needs to consult on a
array_of_transformsto know of which it will use inside the shader to actually get the transform information. "The sprite owns, but it kinda gives this ownership to an array, and now has to consult this array"; weird. This is ok for textures, as the sprite doesn't own the texture. -
The transforms has to be stored inside an array with a buffer-SSBO.
-
This requires a
mem.copyto the region. The desc set is just a host-visible region. There need to be a cpu-struct that holds the information before copying it to this host-visible region, just like:rd.buffer_mapped_set_data(_game.shader_set0_bind0[frame_idx], Scene_Globals_2D{ view_matrix = _game.camera.view_matrix, proj_matrix = _game.camera.proj_matrix, }) -
The desc set does not need to be written/updated. It's just a
mem.copyfrom the cpu-struct to the host-visible region.
-
About
-
Descriptor indexing is also known by the term "bindless", which refers to the fact that binding individual descriptor sets and descriptors is no longer the primary way we keep shader pipelines fed. Instead, we can bind a huge descriptor set once and just index into a large number of descriptors.
-
Adds a lot of flexibility to how resources are accessed.
-
"Bindless algorithms" are generally built around this flexibility where we either index freely into a lot of descriptors at once, or update descriptors where we please. In this model, "binding" descriptors is not a concern anymore.
-
The core functionality of this extension is that we can treat descriptor memory as one massive array, and we can freely access any resource we want at any time, by indexing.
-
If an array is large enough, an index into that array is indistinguishable from a pointer.
-
At most, we need to write/copy descriptors to where we need them and we can now consider descriptors more like memory blobs rather than highly structured API objects.
-
The introduction of descriptor indexing revealed that the descriptor model is all just smoke and mirrors. A descriptor is just a blob of binary data that the GPU can interpret in some meaningful way. The API calls to manage descriptors really just boils down to “copy magic bits here.”
-
Support :
-
Descriptor Indexing was created in 2018, so all hardware 2018+ should support it.
-
Core in Vulkan 1.2+
-
Limits queried using
VkPhysicalDeviceDescriptorIndexingPropertiesEXT. -
Features queried using
VkPhysicalDeviceDescriptorIndexingFeaturesEXT. -
Features toggled using
VkPhysicalDeviceDescriptorIndexingFeaturesEXT.
-
-
Required for :
-
Raytracing.
-
Many GPU Driven Rendering approaches.
-
-
Advantages :
-
No costly transfer of descriptor to GPU every frame. Shows up as spending a lot of time in
vkUpdateDescriptorSets(Vulkan) -
More flexible / dynamic rendering architecture
-
No manual tracking of per-object resource groups
-
Updating matrices and material data can be done in bulk before command recording
-
CPU and GPU refer to resources the same way, by index
-
GPU can store Texture IDs in a buffer for reference later in the frame – many uses
-
Easy Vertex Pulling – gets rid of binding vertex buffers
-
Write resource indexes from one shader into a buffer that another shader reads & uses
-
G-Buffer can use material ID instead of values
-
Terrain Splatmap contains material IDs allowing many materials to be used, instead of 4
-
And more…
-
-
Disadvantages :
-
Requires hardware support
-
May be too new for widespread use
-
Different “feature levels” can help ease transition
-
-
Different Performance Penalties
-
Arrays indexing can cause memory indirections
-
Fetching texture descriptors from an array indexed by material data indexed by material index can add an extra indirection on GPU compared to some alternative designs
-
-
-
“With great power comes great responsibility”
-
GPU can't verify that valid descriptors are bound
-
Validation is costlier: happens inside shaders
-
Can be difficult to debug
-
Descriptor management is up to the Application
-
-
On some hardware, various descriptor set limits may make this technique impractical to implement; to be able to index an arbitrary texture dynamically from the shader,
maxPerStageDescriptorSampledImagesshould be large enough to accomodate all material textures - while many desktop drivers expose a large limit here, the specification only guarantees a limit of 16, so bindless remains out of reach on some hardware that otherwise supports Vulkan.
-
-
Comparison: Indexing resources without the extension :
-
 .
.
-
Descriptor Indexing, explanation of "dynamic non-uniform" .
-
Good read.
-
-
Constant Indexing :
layout(set = 0, binding = 0) uniform sampler2D Tex[4]; texture(Tex[0], ...); texture(Tex[2], ...); // We can trivially flatten a constant-indexed array into individual resources, // so, constant indexing requires no fancy hardware indexing support. layout(set = 0, binding = 0) uniform sampler2D Tex0; layout(set = 0, binding = 1) uniform sampler2D Tex1; layout(set = 0, binding = 2) uniform sampler2D Tex2; layout(set = 0, binding = 3) uniform sampler2D Tex3; -
Image Array Dynamic Indexing :
-
The dynamic indexing features allow us to use a non-constant expression to index an array.
-
This has been supported since Vulkan 1.0.
-
-
The restriction is that the index must be dynamically uniform .
layout(set = 0, binding = 0) uniform sampler2D Tex[4]; texture(Tex[dynamically_uniform_expression], ...); -
-
Non-uniform vs Texture Atlas vs Texture Array :
-
Accessing arbitrary textures in a draw call is not a new problem, and graphics programmers have found ways over the years to workaround restrictions in older APIs. Rather than having multiple textures, it is technically possible to pack multiple textures into one texture resource, and sample from the correct part of the texture. This kind of technique is typically referred to as "texture atlas". Texture arrays (e.g. sampler2DArray) is another feature which can be used for similar purposes.
-
Problems with atlas:
-
Mip-mapping is hard to implement, and must likely be done manually with derivatives and math.
-
Anisotropic filtering is basically impossible.
-
Any other sampler addressing than
CLAMP_TO_EDGEis very awkward to implement. -
Cannot use different texture formats.
-
-
Problems with texture array:
-
All resolutions must match.
-
Number of array layers is limited (just 256 in min-spec).
-
Cannot use different texture formats.
-
-
Non-uniform indexing solves these issues since we can freely use multiple sampled image descriptors instead. Atlases and texture arrays still have their place. There are many use cases where these restrictions do not cause problems.
-
Non-uniform indexing is not just limited to textures (although that is the most relevant use case). Any descriptor type can be used as long as the device supports it.
-
-
Features
-
Update-after-bind :
-
In Vulkan, you generally have to create a
VkDescriptorSetand update it with all descriptors before you callvkCmdBindDescriptorSets. After a set is bound, the descriptor set cannot be updated again until the GPU is done using it. This gives drivers a lot of flexibility in how they access the descriptors. They are free to copy the descriptors and pack them somewhere else, promote them to hardware registers, the list goes on. -
Update-After-Bind gives flexibility to applications instead. Descriptors can be updated at any time as long as they are not actually accessed by the GPU. Descriptors can also be updated while the descriptor set is bound to a command buffer, which enables a "streaming" use case.
-
This means the application doesn’t have to unbind or re-record command buffers just to change descriptors—reducing CPU overhead in some streaming-resource scenarios.
-
-
Concurrent Updates :
-
Another "hidden" feature of update-after-bind is that it is possible to update the descriptor set from multiple threads. This is very useful for true "bindless" since unrelated tasks might want to update descriptors in different parts of the streamed/bindless descriptor set.
-
-
After and after :
-
 .
.
-
-
-
Non-uniform indexing :
-
While update-after-bind adds flexibility to descriptor management, non-uniform indexing adds great flexibility for shaders.
-
It completely removes all restrictions on how we index into arrays, but we must notify our intent to the compiler.
-
Normally, drivers and hardware can assume that the dynamically uniform guarantee holds, and optimize for that case.
-
If we use the
nonuniformEXTdecoration inGL_EXT_nonuniform_qualifierwe can let the compiler know that the guarantee does not necessarily hold, and the compiler will deal with it in the most efficient way possible for the target hardware. The rationale for having to annotate like this is that driver compiler backends would be forced to be more conservative than necessary if applications were not required to usenonuniformEXT. -
When to use it :
-
The invocation group :
-
The invocation group is a set of threads (invocations) which work together to perform a task.
-
In graphics pipelines, the invocation group is all threads which are spawned as part of a single draw command. This includes multiple instances, and for multi-draw-indirect it is limited to a single
gl_DrawID. -
In compute pipelines, the invocation group is a single workgroup, so it’s very easy to know when it is safe to avoid nonuniformEXT.
-
An expression is considered dynamically uniform if all invocations in an invocation group have the same value.
-
In other words, dynamically uniform means that the index is the same across all threads spawned by a draw command.
-
-
-
Interaction with Subgroups :
-
It is very easy to think that dynamically uniform just means "as long as the index is uniform in the subgroup, it’s fine!". This is certainly true for most (desktop) architectures, but not all.
-
It is technically possible that a value can be subgroup uniform, but still not dynamically uniform. Consider a case where we have a workgroup size of 128 threads, with a subgroup size of 32. Even if each subgroup does
subgroupBroadcastFirst()on the index, each subgroup might have different values, and thus, we still technically neednonuniformEXThere. If you know that you have only one subgroup per workgroup however,subgroupBroadcastFirst()is good enough. -
The safe thing to do is to just add
nonuniformEXTif you cannot prove the dynamically uniform property. If the compiler knows that it only really cares about subgroup uniformity, it could trivially optimize awaynonuniformEXT(subgroupBroadcastFirst())anyways. -
The common reason to use subgroups in the first place, is that it was an old workaround for lack of true non-uniform indexing, especially for desktop GPUs. A common pattern would be something like:
-
-
-
Implementation
-
Exemples :
-
odin_cool_engine:
-
odin_cool_engine/src/rp_ui.odin-
It just sends an index to the compute pipeline via push constants.
-
-
odin_cool_engine/src/renderer.odin:725-
It just sends an index to the compute pipeline via push constants.
-
-
-
-
Setup :
-
Check availability of the extension through
vk.EXT_DESCRIPTOR_INDEXING_EXTENSION_NAME+vk.EnumerateDeviceExtensionProperties. -
Check supported features of the extension through
vk.GetPhysicalDeviceFeatures2+vk.PhysicalDeviceDescriptorIndexingFeaturesas thepNextterm.
-
-
VkDescriptorSetLayoutCreateInfo.-
flags-
UPDATE_AFTER_BIND_POOL-
Specifies that descriptor sets using this layout must be allocated from a descriptor pool created with the
UPDATE_AFTER_BINDbit set. -
Descriptor set layouts created with this bit set have alternate limits for the maximum number of descriptors per-stage and per-pipeline layout.
-
The non-UpdateAfterBind limits only count descriptors in sets created without this flag. The UpdateAfterBind limits count all descriptors, but the limits may be higher than the non-UpdateAfterBind limits.
-
-
-
-
-
PARTIALLY_BOUND-
Specifies that descriptors in this binding that are not dynamically used, don't need to contain valid descriptors at the time the descriptors are consumed.
-
A descriptor is 'dynamically used' if any shader invocation executes an instruction that performs any memory access using the descriptor.
-
If a descriptor is not dynamically used, any resource referenced by the descriptor is not considered to be referenced during command execution.
-
-
This provides so it's not necessary to bind every descriptor. Allows a descriptor array binding to function even when not all array elements are written or valid.
-
This is critical if we want to make use of descriptor "streaming". A descriptor only has to be bound if it is actually used by a shader.
-
Without this feature, if you have an array of N descriptors and your shader indexes [0..N-1], all descriptors must be valid; otherwise behavior is undefined even if the shader never touches the uninitialized ones.
-
When enabled, you only need to write descriptors that the shader will index. “Holes” in the array are allowed, provided shader indices never touch them.
-
Use this when you want to leave “holes” in a large descriptor array (i.e. not update every element) without pre-filling unused slots with a fallback texture. When this flag is set, descriptors that are not dynamically used by the shader need not contain valid descriptors — but if the shader actually accesses an unwritten descriptor you still get undefined/invalid results. This is a convenience to avoid writing N fallback descriptors each time.
-
-
VARIABLE_DESCRIPTOR_COUNT-
Allows a descriptor binding to have a variable number of descriptors.
-
Use a variable amount of descriptors in an array.
-
Specifies that this is a variable-sized descriptor binding, whose size will be specified when a descriptor set is allocated using this layout.
-
This must only be used for the last binding in the descriptor set layout (i.e. the binding with the largest value of binding).
-
vk.DescriptorSetLayoutBinding.descriptorCount-
The value is treated as an upper bound on the size of the binding.
-
The actual count is supplied at allocation time via
VkDescriptorSetVariableDescriptorCountAllocateInfo. -
For the purposes of counting against limits such as
maxDescriptorSetandmaxPerStageDescriptor, the full value ofdescriptorCountis counted, except for descriptor bindings with a descriptor type ofDESCRIPTOR_TYPE_INLINE_UNIFORM_BLOCK, whenVkDescriptorSetLayoutCreateInfo.flagsdoes not containDESCRIPTOR_SET_LAYOUT_CREATE_DESCRIPTOR_BUFFER. In this case,descriptorCountspecifies the upper bound on the byte size of the binding; thus it counts against themaxInlineUniformBlockSizeandmaxInlineUniformTotalSizelimits instead.
-
-
When we later allocate the descriptor set, we can declare how large we want the array to be.
-
Be aware that there is a global limit to the number of descriptors can be allocated at any one time.
-
This is extremely useful when using
EXT_descriptor_indexing, since we do not have to allocate a fixed amount of descriptors for each descriptor set. -
In many cases, it is far more flexible to use runtime sized descriptor arrays.
-
Use this when you want the shader-visible length of a descriptor-array binding to be allocatable per-descriptor-set (i.e. different sets expose different array lengths) instead of using a single compile-time/ layout upper bound. At allocation you pass the actual count with VkDescriptorSetVariableDescriptorCountAllocateInfo. This reduces bookkeeping/pool usage and lets you avoid allocating the full upper bound for every set. Requires the descriptor-indexing feature be enabled and the variable-size binding must be the last binding in the set
-
-
UPDATE_AFTER_BIND-
Specifies that if descriptors in this binding are updated between when the descriptor set is bound in a command buffer and when that command buffer is submitted to a queue, then the submission will use the most recently set descriptors for this binding and the updates do not invalidate the command buffer. Descriptor bindings created with this flag are also partially exempt from the external synchronization requirement in
vkUpdateDescriptorSetWithTemplateKHRandvkUpdateDescriptorSets. Multiple descriptors with this flag set can be updated concurrently in different threads, though the same descriptor must not be updated concurrently by two threads. Descriptors with this flag set can be updated concurrently with the set being bound to a command buffer in another thread, but not concurrently with the set being reset or freed. -
Update-after-bind is another critical component of descriptor indexing, which allows us to update descriptors after a descriptor set has been bound to a command buffer.
-
This is critical for streaming descriptors, but it also relaxed threading requirements. Multiple threads can update descriptors concurrently on the same descriptor set.
-
UPDATE_AFTER_BINDdescriptors is somewhat of a precious resource, but min-spec in Vulkan is at least 500k descriptors, which should be more than enough.
-
-
UPDATE_UNUSED_WHILE_PENDING-
Specifies that descriptors in this binding can be updated after a command buffer has bound this descriptor set, or while a command buffer that uses this descriptor set is pending execution, as long as the descriptors that are updated are not used by those command buffers. Descriptor bindings created with this flag are also partially exempt from the external synchronization requirement in vkUpdateDescriptorSetWithTemplateKHR and vkUpdateDescriptorSets in the same way as for
UPDATE_AFTER_BIND. IfPARTIALLY_BOUNDis also set, then descriptors can be updated as long as they are not dynamically used by any shader invocations. IfPARTIALLY_BOUNDis not set, then descriptors can be updated as long as they are not statically used by any shader invocations. -
Update-Unused-While-Pending is somewhat subtle, and allows you to update a descriptor while a command buffer is executing.
-
The only restriction is that the descriptor cannot actually be accessed by the GPU.
-
-
UPDATE_AFTER_BINDvsUPDATE_UNUSED_WHILE_PENDING-
Both involve updates to descriptor sets after they are bound,
UPDATE_UNUSED_WHILE_PENDINGis a weaker requirement since it is only about descriptors that are not used, whereasUPDATE_AFTER_BINDrequires the implementation to observe updates to descriptors that are used.
-
-
-
Enabling Non-Uniform Indexing :
-
Enable
runtimeDescriptorArrayandshaderSampledImageArrayNonUniformIndexing(required for indexing an array ofCOMBINED_IMAGE_SAMPLER),descriptorBindingPartiallyBound(optional, to avoid undefined behavior on not fully populated arrays).-
If in Vulkan <1.2, then the features must be enabled in the
vk.PhysicalDeviceDescriptorIndexingFeatures. -
If in Vulkan >=1.2, then the features must be enabled in the
vk.PhysicalDeviceVulkan12Features.-
If this is not followed, you'll get:
[ERROR] --- vkCreateDevice(): pCreateInfo->pNext chain includes a VkPhysicalDeviceVulkan12Features structure, then it must not include a VkPhysicalDeviceDescriptorIndexingFeatures structure. The features in VkPhysicalDeviceDescriptorIndexingFeatures were promoted in Vulkan 1.2 and is also found in VkPhysicalDeviceVulkan12Features. To prevent one feature setting something to TRUE and the other to FALSE, only one struct containing the feature is allowed. pNext chain: VkDeviceCreateInfo::pNext -> [STRUCTURE_TYPE_LOADER_DEVICE_CREATE_INFO] -> [STRUCTURE_TYPE_LOADER_DEVICE_CREATE_INFO] -> [VkPhysicalDeviceVulkan13Features] -> [VkPhysicalDeviceVulkan12Features] -> [VkPhysicalDeviceDynamicRenderingUnusedAttachmentsFeaturesEXT] -> [VkPhysicalDeviceDescriptorIndexingFeatures]. The Vulkan spec states: If the pNext chain includes a VkPhysicalDeviceVulkan12Features structure, then it must not include a VkPhysicalDevice8BitStorageFeatures, VkPhysicalDeviceShaderAtomicInt64Features, VkPhysicalDeviceShaderFloat16Int8Features, VkPhysicalDeviceDescriptorIndexingFeatures, VkPhysicalDeviceScalarBlockLayoutFeatures, VkPhysicalDeviceImagelessFramebufferFeatures, VkPhysicalDeviceUniformBufferStandardLayoutFeatures, VkPhysicalDeviceShaderSubgroupExtendedTypesFeatures, VkPhysicalDeviceSeparateDepthStencilLayoutsFeatures, VkPhysicalDeviceHostQueryResetFeatures, VkPhysicalDeviceTimelineSemaphoreFeatures, VkPhysicalDeviceBufferDeviceAddressFeatures, or VkPhysicalDeviceVulkanMemoryModelFeatures structure (https://vulkan.lunarg.com/doc/view/1.4.328.0/windows/antora/spec/latest/chapters/devsandqueues.html#VUID-VkDeviceCreateInfo-pNext-02830) -
vulkan12_features := vk.PhysicalDeviceVulkan12Features{ // etc descriptorIndexing = true, // Descriptor Indexing: // Todo: Is this only for VK 1.2? runtimeDescriptorArray = true, // Descriptor Indexing: shaderSampledImageArrayNonUniformIndexing = true, // Descriptor Indexing: required for indexing an array of `COMBINED_IMAGE_SAMPLER`. descriptorBindingPartiallyBound = true, // Descriptor Indexing: optional, to avoid undefined behavior on not fully populated arrays. descriptorBindingVariableDescriptorCount = true, // Descriptor Indexing: Allows a descriptor binding to have a variable number of descriptors. // etc } -
-
In GLSL use the
GL_EXT_nonuniform_qualifierextension and wrap the index withnonuniformEXT(...)(or applynonuniformEXTto the loaded value) so the compiler emits the SPIR-VNonUniformEXTdecoration.
-
In the shader :
-
Constructors and builtin functions, which all have return types that are not qualified by
nonuniformEXT, will not generate nonuniform results.-
Shaders need to use the constructor syntax (or assignment to a
nonuniformEXT-qualified variable) to re-add thenonuniformEXTqualifier to the result of builtin functions. -
Correct:
-
It is important to note that to be 100% correct, we must use:
-
nonuniformEXT(sampler2D()). -
It is the final argument to a call like
texture()which determines if the access is to be considered non-uniform.
-
-
Wrong:
-
It is very common in the wild to see code like:
-
sampler2D(Textures[nonuniformEXT(in_texture_index)], ...) -
This looks very similar to HLSL, but it is somewhat wrong.
-
Generally, it will work on drivers, but it is not technically correct.
-
-
Examples:
-
sampler2D()is such a constructor, so we must addnonuniformEXTafterwards.-
out_frag_color = texture(nonuniformEXT(sampler2D(Textures[in_texture_index], ImmutableSampler)), in_uv);
-
-
-
-
Other use cases:
-
The nonuniform qualifier will propagate up to the final argument which is used in the load/store or atomic operation.
-
Examples:
// At the top #extension GL_EXT_nonuniform_qualifier : require uniform UBO { vec4 data; } UBOs[]; vec4 foo = UBOs[nonuniformEXT(index)].data; buffer SSBO { vec4 data; } SSBOs[]; vec4 foo = SSBOs[nonuniformEXT(index)].data; uniform sampler2D Tex[]; vec4 foo = texture(Tex[nonuniformEXT(index)], uv); uniform uimage2D Img[]; uint count = imageAtomicAdd(Img[nonuniformEXT(index)], uv, val);#version 450 #extension GL_EXT_nonuniform_qualifier : require layout(local_size_x = 64) in; layout(set = 0, binding = 0) uniform sampler2D Combined[]; layout(set = 1, binding = 0) uniform texture2D Tex[]; layout(set = 2, binding = 0) uniform sampler Samp[]; layout(set = 3, binding = 0) uniform U { vec4 v; } UBO[]; layout(set = 4, binding = 0) buffer S { vec4 v; } SSBO[]; layout(set = 5, binding = 0, r32ui) uniform uimage2D Img[]; void main() { uint index = gl_GlobalInvocationID.x; vec2 uv = vec2(gl_GlobalInvocationID.yz) / 1024.0; vec4 a = textureLod(Combined[nonuniformEXT(index)], uv, 0.0); vec4 b = textureLod(nonuniformEXT(sampler2D(Tex[index], Samp[index])), uv, 0.0); vec4 c = UBO[nonuniformEXT(index)].v; vec4 d = SSBO[nonuniformEXT(index)].v; imageAtomicAdd(Img[nonuniformEXT(index)], ivec2(0), floatBitsToUint(a.x + b.y + c.z + d.w)); }
-
-
Caviats:
-
LOD:
-
Using implicit LOD with nonuniformEXT can be spicy! If the threads in a quad do not have the same index, LOD might not be computed correctly.
-
The
quadDivergentImplicitLODproperty lets you know if it will work. -
In this case however, it is completely fine, since the helper lanes in a quad must come from the same primitive, which all have the same flat fragment input.
-
-
-
Avoinding
nonuniformEXT:-
You might consider using subgroup operations to implement
nonuniformEXTon your own. -
This is technically out of spec, since the SPIR-V specification states that to avoid
nonuniformEXT, -
the shader must guarantee that the index is "dynamically uniform".
-
"Dynamically uniform" means the value is the same across all invocations in an "invocation group".
-
The invocation group is defined to be all invocations (threads) for:
-
An entire draw command (for graphics)
-
A single workgroup (for compute).
-
-
Avoiding
nonuniformEXTwith clever programming is far more likely to succeed when writing compute shaders, -
since the workgroup boundary serves as a much easier boundary to control than entire draw commands.
-
It is often possible to match workgroup to subgroup 1:1, unlike graphics where you cannot control how
-
quads are packed into subgroups at all.
-
The recommended approach here is to just let the compiler do its thing to avoid horrible bugs in the future.
-
-
-
-
Enabling Update-After-Bind :
-
In
VkDescriptorSetLayoutCreateInfowe must pass down binding flags in a separate struct withpNext.bindings_count := len(stage_set_layout.bindings) descriptor_bindings_flags := make([]vk.DescriptorBindingFlagsEXT, bindings_count, context.temp_allocator) for i in 0..<len(descriptor_bindings_flags) { descriptor_bindings_flags[i] = { .PARTIALLY_BOUND } } descriptor_bindings_flags[bindings_count - 1] += { .VARIABLE_DESCRIPTOR_COUNT } // Only the last binding supports VARIABLE_DESCRIPTOR_COUNT. descriptor_binding_flags_create_info := vk.DescriptorSetLayoutBindingFlagsCreateInfoEXT{ sType = .DESCRIPTOR_SET_LAYOUT_BINDING_FLAGS_CREATE_INFO_EXT, bindingCount = u32(bindings_count), pBindingFlags = raw_data(descriptor_bindings_flags), pNext = nil, } descriptor_set_layout_create_info := vk.DescriptorSetLayoutCreateInfo{ sType = .DESCRIPTOR_SET_LAYOUT_CREATE_INFO, flags = { }, bindingCount = u32(bindings_count), pBindings = raw_data(stage_set_layout.bindings), pNext = &descriptor_binding_flags_create_info, }// Num Descriptors static constexpr uint32_t NumDescriptorsStreaming = 2048; static constexpr uint32_t NumDescriptorsNonUniform = 64; // Pool uint32_t poolCount = NumDescriptorsStreaming + NumDescriptorsNonUniform; VkDescriptorPoolSize pool_size = vkb::initializers::descriptor_pool_size(DESCRIPTOR_TYPE_SAMPLED_IMAGE, poolCount); VkDescriptorPoolCreateInfo pool = vkb::initializers::descriptor_pool_create_info(1, &pool_size, 2); // Allocate VkDescriptorSetVariableDescriptorCountAllocateInfoEXT variable_info{}; allocate_info.pNext = &variable_info; variable_info.sType = STRUCTURE_TYPE_DESCRIPTOR_SET_VARIABLE_DESCRIPTOR_COUNT_ALLOCATE_INFO_EXT; variable_info.descriptorSetCount = 1; variable_info.pDescriptorCounts = &NumDescriptorsStreaming; CHECK(vkAllocateDescriptorSets(get_device().get_handle(), &allocate_info, &descriptors.descriptor_set_update_after_bind)); variable_info.pDescriptorCounts = &NumDescriptorsNonUniform; CHECK(vkAllocateDescriptorSets(get_device().get_handle(), &allocate_info, &descriptors.descriptor_set_nonuniform)); -
The
VkDescriptorPoolmust also be created withUPDATE_AFTER_BIND. Note that there is global limit to how many UPDATE_AFTER_BIND descriptors can be allocated at any point. The min-spec here is 500k, which should be good enough.
-
Strategy: Descriptor Buffers (
EXT_descriptor_buffer
)
-
Article .
-
Sample .
-
Released on (2022-11-21).
-
TLDR :
-
Descriptor sets are now backed by
VkBufferobjects where youmemcpyin descriptors. DeleteVkDescriptorPoolandVkDescriptorSetfrom the API, and have fun! -
Performance is either equal or better.
-
-
Coming from Descriptor Indexing, we use plain uints instead of actual descriptor sets, there are some design questions that come up.
-
Do we assign one uint per descriptor, or do we try to group them together such that we only need to push one base offset?
-
If we go with the latter, we might end up having to copy descriptors around. If we go with one uint per descriptor, we just added extra indirection on the GPU. GPU throughput might suffer with the added latency.
-
On the other hand, having to group descriptors linearly one after the other can easily lead to copy hell. Copying descriptors is still an abstracted operation that requires API calls to perform, and we cannot perform it on the GPU. The overhead of all these calls in the driver can be quite significant, especially in API layering. I’ve seen up to 10 million calls to “copy descriptor” per second which adds up.
-
Managing descriptors really starts looking more and more like just any other memory management problem. Let’s try translating existing API concepts into what they really are under the hood.
-
vkCreateDescriptorPool-
vkAllocateMemory. Memory type unknown, but likelyHOST_VISIBLEandDEVICE_LOCAL. Size of pool computed from pool entries.
-
-
vkAllocateDescriptorSets-
Linear or arena allocation from pool. Size and alignment computed from
VkDescriptorSetLayout.
-
-
vkUpdateDescriptorSets-
Writes raw descriptor data by copying payload from
VkImageView/VkSampler/VkBufferView. Write offset is deduced fromVkDescriptorSetLayoutand binding. TheVkDescriptorSetcontains a pointer toHOST_VISIBLEmapped CPU memory. Copies are similar.
-
-
vkCmdBindDescriptorSets-
Binds the GPU VA of the
VkDescriptorSetsomehow.
-
-
The descriptor buffer API effectively removes
VkDescriptorPoolandVkDescriptorSet. The APIs now expose lower level detail. -
For example, there’s now a bunch of properties to query:
typedef struct VkPhysicalDeviceDescriptorBufferPropertiesEXT { … size_t samplerDescriptorSize; size_t combinedImageSamplerDescriptorSize; size_t sampledImageDescriptorSize; size_t storageImageDescriptorSize; size_t uniformTexelBufferDescriptorSize; size_t robustUniformTexelBufferDescriptorSize; size_t storageTexelBufferDescriptorSize; size_t robustStorageTexelBufferDescriptorSize; size_t uniformBufferDescriptorSize; size_t robustUniformBufferDescriptorSize; size_t storageBufferDescriptorSize; size_t robustStorageBufferDescriptorSize; size_t inputAttachmentDescriptorSize; size_t accelerationStructureDescriptorSize; … } VkPhysicalDeviceDescriptorBufferPropertiesEXT;
Strategy: Push Descriptor (
VK_KHR_push_descriptor
)
-
Promoted to core in Vulkan 1.4.
-
Last modified date: (2017-09-12).
-
This extension allows descriptors to be written into the command buffer, while the implementation is responsible for managing their memory. Push descriptors may enable easier porting from older APIs and in some cases can be more efficient than writing descriptors into descriptor sets.
-
Sample .
-
New Commands
-
vkCmdPushDescriptorSetKHR
-
-
If Vulkan Version 1.1 or
VK_KHR_descriptor_update_templateis supported:-
vkCmdPushDescriptorSetWithTemplateKHR
-
-
New Structures
-
Extending
VkPhysicalDeviceProperties2:-
VkPhysicalDevicePushDescriptorPropertiesKHR
-
-
-
New Enum Constants
-
VK_KHR_PUSH_DESCRIPTOR_EXTENSION_NAME -
VK_KHR_PUSH_DESCRIPTOR_SPEC_VERSION -
Extending
VkDescriptorSetLayoutCreateFlagBits:-
VK_DESCRIPTOR_SET_LAYOUT_CREATE_PUSH_DESCRIPTOR_BIT_KHR
-
-
Extending VkStructureType:
-
VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_PUSH_DESCRIPTOR_PROPERTIES_KHR
-
-
-
If Vulkan Version 1.1 or VK_KHR_descriptor_update_template is supported:
-
Extending
VkDescriptorUpdateTemplateType:-
VK_DESCRIPTOR_UPDATE_TEMPLATE_TYPE_PUSH_DESCRIPTORS_KHR
-
-
Strategy: Bindful / Classic strategy (Slot-based / Frequency-based)
-
mna (midmidmid):
-
The reason you split up resources into multiple sets is actually to reduce the cost of
vkCmdBindDescriptorSets. The idea being that if you've got one set that holds scene-wide data and a different set that holds object-specific data, you only bind the scene stuff once and then just leave it bound. Then the per-object updates go faster because you're pushing much smaller descriptor sets into whatever special silicon descriptor sets map to on your particular GPU. Note: there are rules about how you have to arrange your sets (so like the scene-wide one has to be at a lower index than the per-object one), and all of the pipelines you use must have compatible layouts for the sets you aren't rebinding every time you switch to a different pipeline. Someone can correct me if I'm wrong, but if you switch to a pipeline that's got an incompatible layout for some descriptor set at index n then all descriptor sets at indices >= n need to be rebound. -
I think the only reason I'd change any of my stuff to bindless is if I hit however many hundreds of thousands of calls to
vkCmdBindDescriptorSetsit takes for descriptors to be a per-frame bottleneck. -
But I find descriptors pretty intuitive and easy to work with.
-
I didn't find them easy to work with when I first came to VK (from GL/D3D11-world), but now that I've got some scaffolding set up to manage them, they're easy sauce.
-
(They actually map pretty well to having worked with old console GPUs where you manage the command queue directly and have to think about resource bindings in terms of physical registers on the GPU. It was helpful to have that background.)
-
If you're working with descriptor sets, then you have lots of little objects whose lifetimes you need to track and manage. Getting them grouped into the appropriate set of pools cuts that number down to something that's not hard to manage. So, for me, I've got a dynamically allocated and recycled set of descriptor pools for stuff that changes every frame, and then I've got my materials grouped into pack files (for fast content loading) and each of those has one descriptor pool for all the sets for all of its materials. Easy peasy. For bindless, you need to figure out how you're going to divide up the big array of descriptors in your one mega set. There's different strategies for doing that. But you'll get a better description of them out of the bindless fans on the server.
-
Implementation-wise, I don't think there's a huge complexity difference between the two approaches. Bindless might be conceptually simpler since "it's just a big array" doesn't require as big of a mental shift as dividing resources up by usage and update frequency and thinking in those terms.
-
-
In the “classic” model, before you draw or dispatch, you must bind each resource to a specific descriptor binding or slot.
-
Example:
-
vkCmdBindDescriptorSets(...) -
Binding texture #0 for this draw, texture #1 for that draw, etc.
-
-
The shader uses a fixed binding index:
-
layout(set = 0, binding = 3) uniform sampler2D tex;
-
-
If you want to change which texture is used, you re-bind that descriptor.
-
 .
.
Specialization Constants
-
Allows a constant value in SPIR-V to be specified at
VkPipelinecreation time. -
This is powerful as it replaces the idea of doing preprocessor macros in the high level shading language (GLSL, HLSL, etc).
-
A way to provide constant values to a SPIR-V shader at pipeline creation time so the compiler can constant-fold, inline, and eliminate branches.
-
This yields code equivalent to having compiled separate shader variants with those constant values baked in.
-
-
This is not Vulkan exclusive, but an optimization from SPIR-V. OpenGL 4.6 can also use this feature.
-
Sample .
-
UBOs and Push Constants suffer from limited optimizations during shader compilation. Specialization Constants can provide those optimizations:
-
Uniform buffer objects (UBOs) are one of the most common approaches when it is necessary to set values within a shader at run-time and are used in many tutorials. UBOs are pushed to the shader just prior to its execution, this is after shader compilation which occurs during
vkCreateGraphicsPipelines. As these values are set after the shader has been compiled, the driver’s shader compiler has limited scope to perform optimizations to the shader during its compilation. This is because optimizations such as loop unrolling or unused code removal require the compiler to have knowledge of the values controlling them which is not possible with UBOs. Push constants also suffer from the same problems as UBOs, as they are also provided after the shader has been compiled. -
Specialization Constants are set before pipeline creation meaning these values are known during shader compilation, this allows the driver’s shader compiler to perform optimizations. In this optimisation process the compiler has the ability to remove unused code blocks and statically unroll which reduces the fragment cycles required by the shader which results in increased performance.
-
While specialization constants rely on knowing the required values before pipeline creation occurs, by trading off this flexibility and allowing the compiler to perform these optimizations you can increase the performance of your application easily and reduce shader code size.
-
-
Do :
-
Use compile-time specialization constants for all control flow. This allows compilation to completely remove unused code blocks and statically unroll loops.
-
-
Don’t :
-
Use control-flow which is parameterized by uniform values; specialize shaders for each control path needed instead.
-
-
Impact :
-
Reduced performance due to less efficient shader programs.
-
-
Example :
#version 450 layout (constant_id = 0) const float myColor = 1.0; layout(location = 0) out vec4 outColor; void main() { outColor = vec4(myColor); }struct myData { float myColor = 1.0f; } myData; VkSpecializationMapEntry mapEntry = {}; mapEntry.constantID = 0; // matches constant_id in GLSL and SpecId in SPIR-V mapEntry.offset = 0; mapEntry.size = sizeof(float); VkSpecializationInfo specializationInfo = {}; specializationInfo.mapEntryCount = 1; specializationInfo.pMapEntries = &mapEntry; specializationInfo.dataSize = sizeof(myData); specializationInfo.pData = &myData; VkGraphicsPipelineCreateInfo pipelineInfo = {}; pipelineInfo.pStages[fragIndex].pSpecializationInfo = &specializationInfo; // Create first pipeline with myColor as 1.0 vkCreateGraphicsPipelines(&pipelineInfo); // Create second pipeline with same shader, but sets different value myData.myColor = 0.5f; vkCreateGraphicsPipelines(&pipelineInfo); -
Use cases :
-
Toggling features:
-
Support for a feature in Vulkan isn’t known until runtime. This usage of specialization constants is to prevent writing two separate shaders, but instead embedding a constant runtime decision.
-
-
Improving backend optimizations:
-
Optimizing shader compilation from SPIR-V to GPU.
-
The “backend” here refers to the implementation’s compiler that takes the resulting SPIR-V and lowers it down to some ISA to run on the device.
-
Constant values allow a set of optimizations such as constant folding , dead code elimination , etc. to occur.
-
-
Affecting types and memory sizes:
-
It is possible to set the length of an array or a variable type used through a specialization constant.
-
It is important to notice that a compiler will need to allocate registers depending on these types and sizes. This means it is likely that a pipeline cache will fail if the difference is significant in registers allocated.
-
-
-
How they work :
-
The values are supplied using
VkSpecializationInfoattached to theVkPipelineShaderStageCreateInfo. -
In GLSL (or HLSL → SPIR-V) mark a constant with a constant id, e.g.
layout(constant_id = 0) const int MATERIAL_MODE = 0; -
Create
VkSpecializationMapEntryentries mappingconstantID→ offset/size in your data block. -
Fill a contiguous data buffer with the specialization values and set up
VkSpecializationInfo. -
Put the
VkSpecializationInfo*into the shader stageVkPipelineShaderStageCreateInfobefore callingvkCreateGraphicsPipelines. The backend finalizes (specializes/compiles) the shader at pipeline creation time.
-
-
How it affects the pipeline workflow :
-
TLDR :
-
It does not solve the pipeline workflow problem. It provides a system for shader optimization at SPIR-V→GPU compile time.
-
Specialization lets you get near-compile-time optimizations while still selecting variants at runtime, but it does not avoid having multiple created pipelines if you need multiple different specialized behaviors.
-
-
They do not, by themselves, precompile every possible branch permutation and keep them all resident for you. Each distinct set of specialization values that you want available at runtime normally corresponds to a separately created pipeline (the specialization values are applied during pipeline creation).
-
If you need multiple variants you must create (or reuse) the pipelines for those values.
-
If you have N independent boolean specialization choices, the number of possible specialized pipelines is 2^N (exponential growth). Creating many pipelines increases driver/state memory and creation time; use caching/derivatives/libraries if creation cost or count is a concern.
-
You cannot change a specialization constant per draw without binding a different pipeline: the specialization is fixed for the pipeline object, so per-draw changes require binding another pipeline or using a different strategy (uniforms, push constants, dynamic branching).
-
Different values mean different pipeline creation (driver work / memory).
-
"Is this a way to precompile every branching of a shader?"
-
Yes, but only if you actually create a pipeline for each variant.
-
Specialization constants let the driver compile-away branches at pipeline-creation time, but they do not magically produce all variants for you at draw time.
-
-
-
Recommendations :
-
Improving shader performance with vulkan's specialization constants .
-
When we create the Vulkan pipeline, we pass this specialization information using the
pSpecializationInfofield ofVkPipelineShaderStageCreateInfo. At that point, the driver will override the default value of the specialization constant with the value provided here before the shader code is optimized and native GPU code is generated, which allows the driver compiler backend to generate optimal code. -
It is possible to compile the same shader with different constant values in different pipelines, so even if a value changes often, so long as we have a finite number of combinations, we can generate optimized pipelines for each one ahead of the start of the rendering loop and just swap pipelines as needed while rendering.
-
"promote the UBO array to a push constant".
-
Applying specialization constants in a small number of shaders allowed me to benefit from loop unrolling and, most importantly, UBO promotion to push constants in the SSAO pass, obtaining performance improvements that ranged from 10% up to 20% depending on the configuration.
-
In other words:
-
The article shows how it's possible to pass a value to the shader during graphics pipeline creation so the shader is compiled from SPIR-V to GPU with that constant altered.
-
This helps by allowing the SPIR-V→GPU compiler to make optimization choices such as unrolling loops and removing branches; it can also enable UBO promotion.
-
The article does not suggest specialization constants solve the pipeline workflow problem. It focuses on compile-time shader optimizations.
-
-
-
Physical Storage Buffer (
KHR_buffer_device_address
)
-
Impressions :
-
(2025-09-08)
-
No descriptor sets.
-
Cool.
-
-
Very easy to set up.
-
Shader usage is a bit tricky; push constants are required to access buffers in many patterns.
-
More prone to programmer errors because there is no automatic bounds checking.
-
Hmm, idk, for now not sure.
-
-
Adds the ability to have “pointers in the shader”.
-
Buffer device address is a powerful and unique feature of Vulkan. It exposes GPU virtual addresses directly to the application, and the application can then use those addresses to access buffer data freely through pointers rather than descriptors.
-
This feature lets you place addresses in buffers and load and store to them inside shaders, with full capability to perform pointer arithmetic and other tricks.
-
Support :
-
Core in Vulkan 1.3.
-
Submitted at (2019-01-06), core at (2019-11-25).
-
Coverage :
-
(2025-09-08) 71.6%
-
79.8% Windows
-
70.9% Linux
-
68.7% Android
-
-
-
Lack of safety :
-
A critical thing to note is that a raw pointer has no idea of how much memory is safe to access. Unlike SSBOs when bounds-checking features are enabled, you must either do range checks yourself or avoid relying on out-of-bounds behavior.
-
-
Creating a buffer :
-
To be able to grab a device address from a
VkBuffer, you must create the buffer withSHADER_DEVICE_ADDRESSusage. -
The memory you bind that buffer to must be allocated with the corresponding flag via
pNext.
VkMemoryAllocateFlagsInfoKHR flags_info{STRUCTURE_TYPE_MEMORY_ALLOCATE_FLAGS_INFO_KHR}; flags_info.flags = MEMORY_ALLOCATE_DEVICE_ADDRESS_KHR; memory_allocation_info.pNext = &flags_info;-
After allocating and binding the buffer, query the address:
VkBufferDeviceAddressInfoKHR address_info{STRUCTURE_TYPE_BUFFER_DEVICE_ADDRESS_INFO_KHR}; address_info.buffer = buffer.buffer; buffer.gpu_address = vkGetBufferDeviceAddressKHR(device, &address_info);-
This address behaves like a normal address; you can offset the
VkDeviceAddressvalue as you see fit since it is auint64_t. -
There is no host-side alignment requirement enforced by the API for this value.
-
When using this pointer in shaders, you must provide and respect alignment semantics yourself, because the shader compiler cannot infer anything about a raw pointer loaded from memory.
-
You can place this pointer inside another buffer and use it as an indirection.
-
-
GL_EXT_buffer_reference:-
In Vulkan GLSL, the
GL_EXT_buffer_referenceextension allows declaring buffer blocks as pointer-like types rather than SSBOs. GLSL lacks true pointer types, so this extension exposes pointer-like behavior.
#extension GL_EXT_buffer_reference : require-
You can forward-declare types. Useful for linked lists and similar structures.
layout(buffer_reference) buffer Position;-
You can declare a buffer reference type. This is not an SSBO declaration, but effectively a pointer-to-struct.
layout(std430, buffer_reference, buffer_reference_align = 8) writeonly buffer Position { vec2 positions[]; };-
buffer_referencetags the type accordingly.buffer_reference_alignmarks the minimum alignment for pointers of this type. -
You can place the
Positiontype inside another buffer or another buffer reference type:
layout(std430, buffer_reference, buffer_reference_align = 8) readonly buffer PositionReferences { Position buffers[]; };-
Now you have an array of pointers.
-
You can also place a buffer reference inside push constants, an SSBO, or a UBO.
layout(std430, set = 0, binding = 0) readonly buffer Pointers { Positions positions[]; }; layout(std430, push_constant) uniform Registers { PositionReferences references; } registers; -
-
Casting pointers :
-
A key aspect of buffer device address is that we gain the capability to cast pointers freely.
-
While it is technically possible (and useful in some cases!) to "cast pointers" with SSBOs with clever use of aliased declarations like so:
layout(set = 0, binding = 0) buffer SSBO { float v1[]; }; layout(set = 0, binding = 0) buffer SSBO2 { vec4 v4[]; };-
It gets kind of hairy quickly, and not as flexible when dealing with composite types.
-
When we have casts between integers and pointers, we get the full madness that is pointer arithmetic. Nothing stops us from doing:
#extension GL_EXT_buffer_reference : require layout(buffer_reference) buffer PointerToFloat { float v; }; PointerToFloat pointer = load_pointer(); uint64_t int_pointer = uint64_t(pointer); int_pointer += offset; pointer = PointerToFloat(int_pointer); pointer.v = 42.0;-
Not all GPUs support 64-bit integers, so it is also possible to use
uvec2to represent pointers. This way, we can do raw pointer arithmetic in 32-bit, which might be more optimal anyways.
#extension GL_EXT_buffer_reference_uvec2 : require layout(buffer_reference) buffer PointerToFloat { float v; }; PointerToFloat pointer = load_pointer(); uvec2 int_pointer = uvec2(pointer); uint carry; uint lo = uaddCarry(int_pointer.x, offset, carry); uint hi = int_pointer.y + carry; pointer = PointerToFloat(uvec2(lo, hi)); pointer.v = 42.0; -
-
Debugging :
-
When debugging or capturing an application that uses buffer device addresses, there are some special driver requirements that are not universally supported. Essentially, to be able to capture application buffers which contain raw pointers, we must ensure that the device address for a given buffer remains stable when the capture is replayed in a new process. Applications do not have to do anything here, since tools like RenderDoc will enable the
bufferDeviceAddressCaptureReplayfeature for you, and deal with all the magic associated with address capture behind the scenes. If thebufferDeviceAddressCaptureReplayis not present however, tools like RenderDoc will mask out thebufferDeviceAddressfeature, so beware.
-
-
Sample .
-
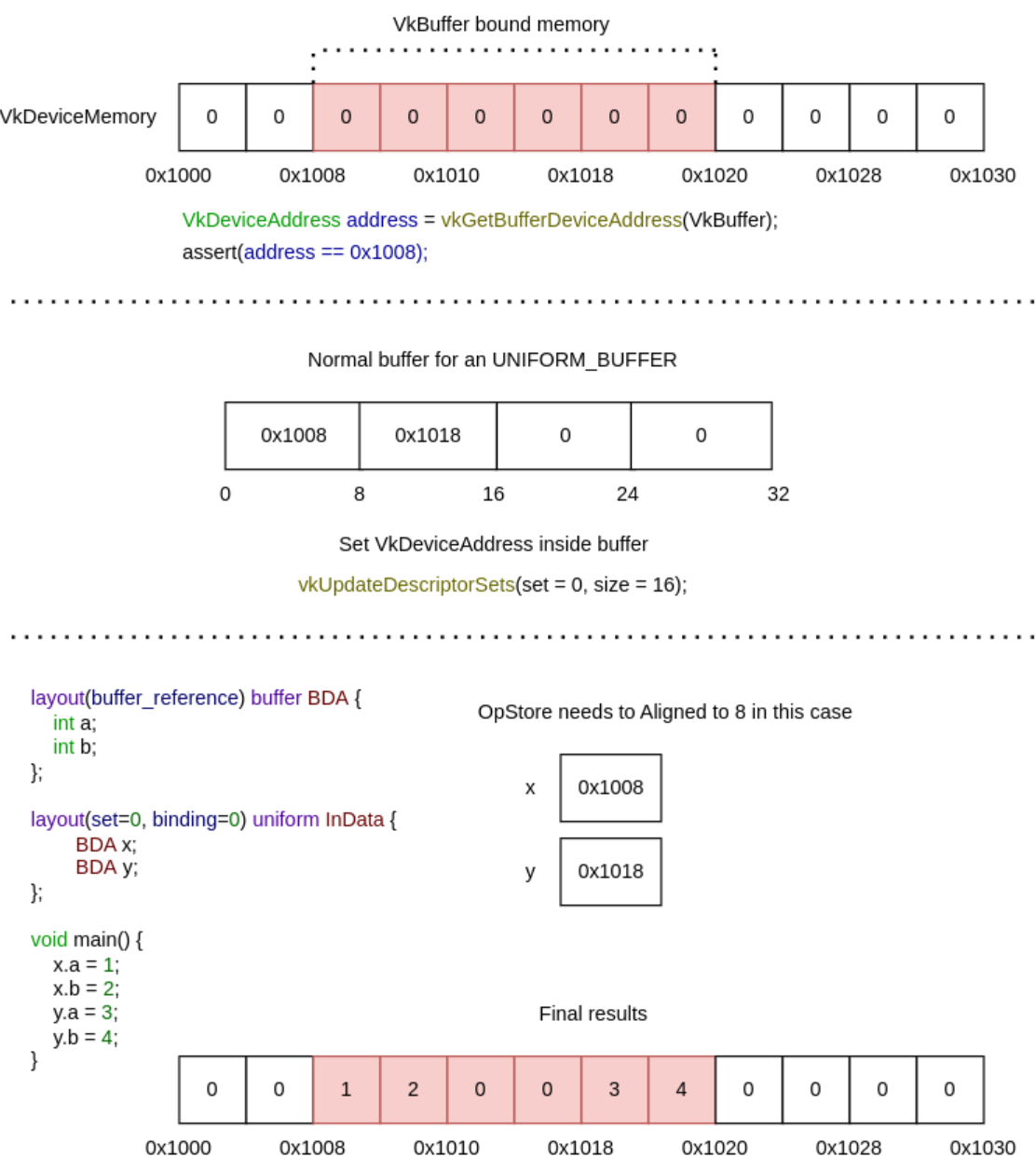 .
.