-
-
Very very interesting read.
-
There's quite a lot of yapping about things that don't quite correlate to the problem, but even so, it's a great read.
-
I stopped at "Searching" (node7); I haven't read it yet.
-
Philosophy
-

-
This example class includes many of the types of things found in games, where the codebase has grown organically. It's common for the Player class to have lots of helper functions to make writing game code easier. Helper functions typically consider the Player as an instance in itself, from data in save through to rendering on screen. It's not unusual for the Player class to touch nearly every aspect of a game, as the human player is the target of the code in the first place, the Player class is going to reference nearly everything too.
-
AI characters will have similarly gnarly looking classes if they are generalized rather than specialized. Specializing AI was more commonplace when games needed to fit in smaller machines, but now, because the Player class has to interact with many of them over the course of the game, they tend to be unified into one type just like the player, if not the same as the player, to help simplify the code that allows them to interact. As of writing, the way in which AI is differentiated is mostly by data, with behavior trees taking the main stage for driving how AI thinks about its world. Behavior trees are another concept subject to various interpretations, so some forms are data-oriented design friendly, and others are not.
-
A recurring theme in articles and post-mortems from people moving from object-oriented hierarchies of gameplay classes to a component based approach is the transitional states of turning their classes into containers of smaller objects, an approach often called composition. This transitional form takes an existing class and finds the boundaries between concepts internal to the class and attempts to refactor them out into new classes which can be owned or pointed to by the original class. From our monolithic player class, we can see there are lots of things that are not directly related, but that does not mean they are not linked together.
-
Object-oriented hierarchies are is-a relationships, and components and composition oriented designs are traditionally thought of as has-a relationships. Moving from one to the other can be thought of as delegating responsibility or moving away from being locked into what you are, but having a looser role and keeping the specialization until further down the tree. Composition clears up most of the common cases of diamond inheritance issues, as capabilities of the classes are added by accretion as much as they are added by overriding.
-
The first move we need to make will be to take related pieces of our monolithic class and move them into their own classes, along the lines of composing, changing the class from owning all the data and the actions that modify the data into having instances which contain data and delegating actions down into those specialized structures where possible. We move the data out into separate structures so they can be more easily combined into new classes later. We will initially only separate by categories we perceive as being the boundaries between systems. For example, we separate rendering from controller input, from gameplay details such as inventory, and we split out animation from all.
-
Taking a look at the results of splitting the player class up, such as in listing [*], it's possible to make some initial assessments of how this may turn out. We can see how a first pass of building a class out of smaller classes can help organize the data into distinct, purpose oriented collections, but we can also see the reason why a class ends up being a tangled mess. When you think about the needs of each of the pieces, what their data requirements are, the coupling can become evident. The rendering functions need access to the player's position as well as the model, and the gameplay functions such as Shoot(Vec target) need access to the inventory as well as setting animations and dealing damage. Taking damage will need access to the animations and health. Things are already seeming more difficult to handle than expected, but what's really happening here is that it's becoming clear that code needs to cut across different pieces of data. With just this first pass, we can start to see that functionality and data don't belong together.
-
In this first step, we made the player class a container for the components. Currently, the player has the components, and the player class has to be instantiated to make a player exist. To allow for the cleanest separation into components in the most reusable way, it's worth attempting to move components into being managed by managers, and not handled or updated by their entities. In doing this, there will also be a benefit of cache locality when we're iterating over multiple entities doing related tasks when we move them away from their owners.
-
This is where it gets a bit philosophical . Each system has an idea of the data it needs in order to function, and even though they will overlap, they will not share all data. Consider what it is that a serialization system needs to know about a character. It is unlikely to care about the current state of the animation system, but it will care about inventory. The rendering system will care about position and animation, but won't care about the current amount of ammo. The UI rendering code won't even care about where the player is, but will care about inventory and their health and damage. This difference of interest is at the heart of why putting all the data in one class isn't a good long-term solution .
-
The functionality of a class, or an object, comes from how the internal state is interpreted, and how the changes to state over time are interpreted too. The relationship between facts is part of the problem domain and could be called meaning, but the facts are only raw data . This separation of fact from meaning is not possible with an object-oriented approach, which is why every time a fact acquires a new meaning, the meaning has to be implemented as part of the class containing the fact. Dissolving the class, extracting the facts and keeping them as separate components, has given us the chance to move away from classes that instill permanent meaning at the expense of occasionally having to look up facts via less direct methods. Rather than store all the possibly associated data by meaning, we choose to only add meaning when necessary. We add meaning when it is part of the immediate problem we are trying to solve.
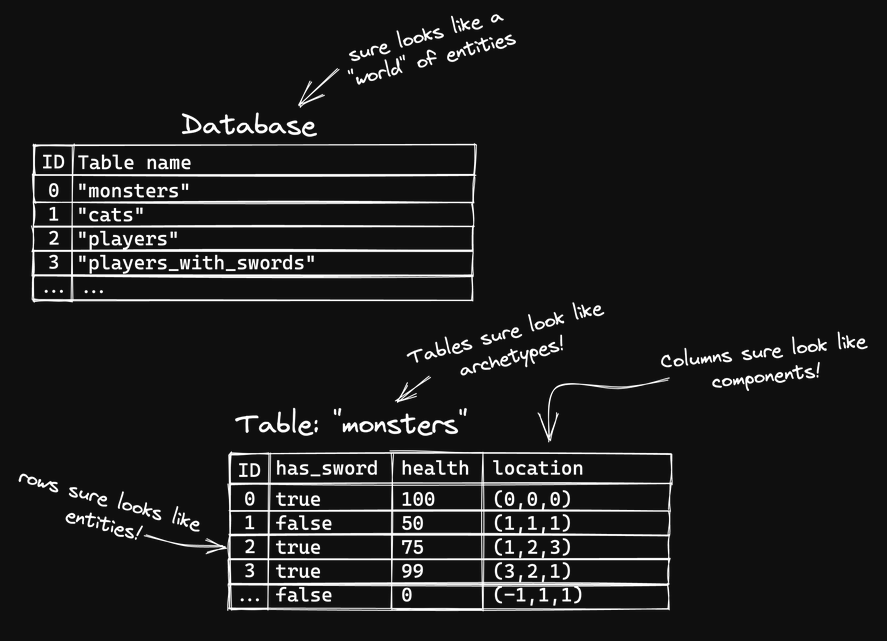
Relational Databases
-
You certainly don't have to move your data to a database style to do data-oriented design, but there are many places where you will wish you had a simple array to work with.
-
Edgar F. Codd proposed the relational model to handle the current and future needs of agents interacting with data. He proposed a solution to structuring data for insert, update, delete, and query operations. His proposal claimed to reduce the need to maintain a deep understanding of how the data was laid out to use it well. His proposal also claimed to reduce the likelihood of introducing internal inconsistencies. He introduced the fundamental terms of normalization we use to this day in a systematic approach to reducing the most complex of interconnected state information to linear lists of unique independent tuples.
-
What we see here as we normalize our data is a tendency to split data by dependency. Looking at many third party engines and APIs, you can see some parallels with the results of these normalization. It's unlikely that the people involved in the design and evolution of these engines took their data and applied database normalization techniques, but sometimes the separations between object and components of objects can be obvious enough that you don't need a formal technique in order to realize some positive structural changes.
-
In some games, the entity object is not just an object that can be anything, but is instead a specific subset of the types of entity involved in the game. For example, in one game there might be a class for the player character, and one for each major type of enemy character, and another for vehicles. The player may have different attributes to other entities, such as lacking AI controls, or having player controls, or having regenerating health, or having ammo. This object-oriented approach puts a line, invisible to the user, but intrusive to the developer, between classes of object and their instances. It is intrusive because when classes touch, they have to adapt to each other. When they don't reside in the same hierarchy, they have to work through abstraction layers to message each other. The amount of code required to bridge these gaps can be small, but they always introduce complexity.
-
When developing software, this usually manifests as time spent writing out templated code that can operate on multiple classes rather than refactoring the classes involved into more discrete components. This could be considered wasted time as the likelihood of other operations needing to operate on all the objects is greater than zero, and the effort to refactor into components is usually similar to the effort to create a working templated operation.
-
Without classes to define boundaries, the table-based approach levels the playing field for data to be manipulated together. In all cases on our journey through normalizing the level data, we have made it so changes to the design require fewer changes to the data, and made it so data changes are less likely to cause the state to become inconsistent. In many cases, it would seem we have added complexity when it wasn't necessary, and that's up to experimentation and experience to help you decide how far to go.
-
We saw that sometimes adding new features required nothing more than adding a new table, or a new column to an existing table. That's a non-intrusive modification if you are using a database style of storage, but a significant change if you're adding a new member to a class.
-
 .
.
-
 .
.
What should be a column / What should be a component
-
It's not about the TYPE of the data, but how this data is PROCESSED.
-
The granularity can be rooted in considering the data from the perspective of human perception.
-
We use meaningful boundary that gives us the our definition of atomicity for software developed for humans.
-
Try to stay at the level of nouns, the nameable pieces.
-
Examples :
-
Grouping
timer.Timermight make sense, as all timers are processed the same, by just callingtimer.update(&t)on it. -
Grouping
rd.Spritemight not make sense, as one sprite might not be "processed" with another sprite; in this case processed could mean changing it's position or drawing (the draw order can vary if applying Y-Sort). -
Grouping
f32doesn't make sense, as the data is so generic that doesn't tell us anything about how it should be processed. -
A whole song can be an atom, but so is a single tick sound of a clock. A whole page of text is an atom, but so is the player's gamer-tag.
-
Adding sounds, textures, and meshes to this seems quite natural once you realize all these things are resources which if cut into smaller pieces begin to lose what it is that makes them what they are.
-
Half of a sentence is a lot less useful than a whole one, and loses integrity by disassociation. A slice of a sentence is clearly not reusable in any meaningful way with another random slice of a different sentence.
-
Think of raw assets (sounds, textures, vertex buffers, etc.) as primitives, much like the integers, floating point numbers, strings and boolean values.
-
Operations
-
When you use objects, you call methods on them, so how do you unlock a door in this table-based approach? Actions are always going to be insert, delete, or updates. These were clearly specified in Edgar F. Codd's works, and they are all you need to manipulate a relational model.
-
In a real database, finding what mesh to load, or whether a door is locked would normally require a join between tables. A real database would also attempt to optimize the join by changing the sequence of operations until it had made the smallest possible expected workload. We can do better than that because we can take absolute charge of how we look at and request data from our tables. To find out if a door is locked, we don't need to join tables, we know we can look up into the locked doors table directly. Just because the data is laid out like a database, doesn't mean we have to use a query language to access it.
-
When it comes to operations that change state, it's best to try to stick to the kind of operation you would normally find in a DBMS, as doing unexpected operations brings unexpected state complexity. For example, imagine you have a table of doors that are open, and a table of doors that are closed. Moving a door from one table might be considered wasteful, so you may consider changing the representation to a single table, but with all closed doors at one end, and all open at the other. By having both tables represented as a single table, and having the isClosed attribute defined implicitly by a cut-off point in the array, such as in listing [*], leads to the table being somewhat ordered. This type of memory optimization comes at a price. Introducing order into a table makes the whole table inherently less parallelizable to operations, so beware the additional complexity introduced by making changes like this, and document them well.
-
 .
.
-
Unlocking a door can be a delete. A door is locked because there is an entry in the LockedDoors table that matches the Door you are interested in. Unlocking a door is a delete if door matches, and you have the right key.
-
The player inventory would be a table with just PickupIDs. This is the idea that "the primary key is also the data" mentioned much earlier. If the player enters a room and picks up a Pickup, then the entry matching the room is deleted while the inventory is updated to include the new PickupID.
-
Databases have the concept of triggers, where operations on a table can cause cascades of further operations. In the case of picking up a key, we would want a trigger on insert into the inventory that joins the new PickupID with the LockedDoors table. For each matching row, delete it, and now the door is unlocked.
Stream Processing (no global memory)
-
Stream processing means to process data without writing to variables external to the process. This means not allowing things like global accumulators, or accessing global memory not set as a source for the process. This ensures the processes or transforms are trivially parallelizable.
-
When you prepare a primitive render for a graphics card, you set up constants such as the transform matrix, the texture binding, any lighting values, or which shader you want to run. When you come to run the shader, each vertex and pixel may have its own scratchpad of local variables, but they never write to globals or refer to a global scratchpad. The concept of shared memory in general purpose GPU code, such as CUDA and OpenCL, allows the use of a kind of managed cache. None of the GPGPU techniques offer access to global memory, and thus maintain a clear separation of domains and continue to guarantee no side-effects caused by any kernels being run outside of their own sandboxed shared memory. By enforcing this lack of side-effects, we can guarantee trivial parallelism because the order of operations are assured to be irrelevant. If a shader was allowed to write to globals, there would be locking, or it would become an inherently serial operation. Neither of these are good for massive core count devices like graphics cards, so that has been a self imposed limit and an important factor in their design. Adding shared memory to the mix starts to inject some potential locking into the process, and hence is explicitly only used when writing compute shaders.
-
Doing all processing this way, without globals / global scratchpads, gives you the rigidity of intention to highly parallelize your processing and make it easier to think about the system, inspect it, debug it, and extend it or interrupt it to hook in new features. If you know the order doesn't matter, it's very easy to rerun any tests or transforms that have caused bad state.
Ownership
-
Where once we would have an object instance for an area in a game, and we would interrogate it for exits that take us to other areas, now we look into a structure that only contains links between areas, and filter by the area we are in. This reversal of ownership can be a massive benefit in debugging, but can sometimes appear backward when all you want to do is find out what exits are available to get out of an area.
Existential processing
-
Attempts to provide a way to remove unnecessary querying about whether or not to process your data. In most software, there are checks for NULL and queries to make sure the objects are in a valid state before work is started. What if you could always guarantee your pointers were not null? What if you were able to trust that your objects were in a valid state, and should always be processed?
-
If you use existential processing techniques, your classes defined by the tables they belong to, then you can switch between tables at runtime.
Enums
-
The reason why you would put an enum in table form, is to reduce control flow impact. Given this, it's when we aren't using the enumerations to control instruction flow that it's fine to leave them alone. Another possibility is when the value of the enum changes with great frequency, as moving objects from table to table has a cost too.
-
Enumerations are used to define sets of states. We could have had a state variable for the regenerating entity, one that had
in_full_health,is_hurt,is_deadas its three states. We could have had a team index variable for the avoidance entity enumerating all the available teams. Instead, we used tables to provide all the information we needed, as there were only two teams. Any enum can be emulated with a variety of tables. All you need is one table per enumerable value. Setting the enumeration is an insert into a table or a migration from one table to another. -
When using tables to replace enums, some things become more difficult: finding out the value of an enum in an entity is difficult as it requires checking all the tables which represent that state for the entity. However, the main reason for getting the value is either to do an operation based on an external state or to find out if an entity is in the right state to be considered for an operation. This is disallowed and unnecessary for the most part, as firstly, accessing external state is not valid in a pure function, and secondly, any dependent data should already be part of the table element.
-
If the enum is a state or type enum previously handled by a switch or virtual call, then we don't need to look up the value, instead, we change the way we think about the problem. The solution is to run transforms taking the content of each of the switch cases or virtual methods as the operation to apply to the appropriate table, the table corresponding to the original enumeration value.
-
If the enum is instead used to determine whether or not an entity can be operated upon, such as for reasons of compatibility, then consider an auxiliary table to represent being in a compatible state. If you're thinking about the case where you have an entity as the result of a query and need to know if it is in a certain state before deciding to commit some changes, consider that the compatibility you seek could have been part of the criteria for generating the output table in the first place, or a second filtering operation could be committed to create a table in the right form.
-
Examples of enumerations that make sense are keybindings, enumerations of colors, or good names for small finite sets of values. Functions that return enums, such as collision responses (none, penetrating, through). Any kind of enumeration which is actually a lookup into data of another form is good, where the enum is being used to rationalize the access to those larger or harder to remember data tables. There is also a benefit to some enums in that they will help you trap unhandled cases in switches, and to some extent, they are a self-documenting feature in most languages.
Polymorphism
-
Let's consider now how we implement polymorphism. We know we don't have to use a virtual table pointer; we could use an enum as a type variable. That variable, the member of the structure that defines at runtime what that structure should be capable of and how it is meant to react. That variable will be used to direct the choice of functions called when methods are called on the object.
-
When your type is defined by a member type variable, it's usual to implement virtual functions as switches based on that type, or as an array of functions. If we want to allow for runtime loaded libraries, then we would need a system to update which functions are called. The humble switch is unable to accommodate this, but the array of functions could be modified at runtime.
-
We have a solution, but it's not elegant, or efficient. The data is still in charge of the instructions, and we suffer the same instruction cache misses and branch mispredictions as whenever a virtual function is unexpected. However, when we don't really use enums, but instead tables that represent each possible value of an enum, it is still possible to keep compatible with dynamic library loading the same as with pointer based polymorphism, but we also gain the efficiency of a data-flow processing approach to processing heterogeneous types.
-
For each class, instead of a class declaration, we have a factory that produces the correct selection of table insert calls. Instead of a polymorphic method call, we utilize existential processing. Our elements in tables allow the characteristics of the class to be implicit. Creating your classes with factories can easily be extended by runtime loaded libraries. Registering a new factory should be simple as long as there is a data-driven factory method. The processing of the tables and their update() functions would also be added to the main loop.
-
If you create your classes by composition, and you allow the state to change by inserting and removing from tables, then you also allow yourself access to dynamic runtime polymorphism. This is a feature normally only available when dynamically responding via a switch.
-
Polymorphism is the ability for an instance in a program to react to a common entry point in different ways due only to the nature of the instance. In C++, compile-time polymorphism can be implemented through templates and overloading. Runtime polymorphism is the ability for a class to provide a different implementation for a common base operation with the class type unknown at compile-time. C++ handles this through virtual tables, calling the right function at runtime based on the type hidden in the virtual table pointer at the start of the memory pointed to by the this pointer. Dynamic runtime polymorphism is when a class can react to a common call signature in different ways based on its type, but its type can change at runtime. C++ doesn't implement this explicitly, but if a class allows the use of an internal state variable or variables, it can provide differing reactions based on the state as well as the core language runtime virtual table lookup. Other languages which define their classes more fluidly, such as Python, allow each instance to update how it responds to messages, but most of these languages have very poor general performance as the dispatch mechanism has been built on top of dynamic lookup.
Events
-
Using your existence in a table as the registration technique makes this simpler than before and lets you register and de-register with great pace. Subscription becomes an insert, and unsubscribing a delete. It's possible to have global tables for subscribing to global events. It would also be possible to have named tables. Named tables would allow a subscriber to subscribe to events before the publisher exists.
SOA
-
It is okay to keep hot and cold data side by side in an SoA object as data is pulled into the cache by necessity rather than by accidental physical location.
-
Database technology was here first. In DBMS terms, it's called column-oriented databases and they provide better throughput for data processing over traditional row-oriented relational databases simply because irrelevant data is not loaded when doing column aggregations or filtering.
-
For getting the "average age of a population":
-
-


