-
Normalization 1NF, 2NF, 3NF, 4NF, 5NF .
-
At the end of the video there is a summary of all the “Normal Forms”.
-
-
 .
.
Not normalized
-
 .
.
-
DoD Book:
-
 .
.
-
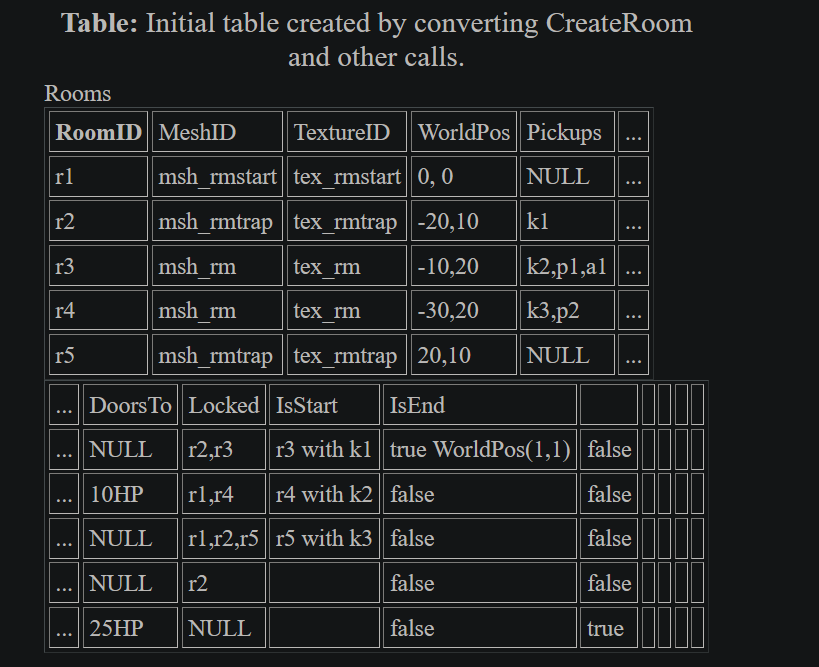
The table
DoorsTo, Locked, etcis a continuation of the tableRoomID, MeshID, TextureID, etc.
-
-
The NULLs in the rows replace the optional content of the objects. If an object instance doesn't have a certain attribute then we replace those features with NULLs. There are also elements which contain more than one item of data.
-
Having multiple doors per room is tricky to handle in this table. How would you figure out what doors it had? The same goes for whether the door is locked, and whether there are any pickups. The first stage in normalizing is going to be reducing the number of elements in each cell to 1, and increasing it to 1 where it's currently NULL.
-
1NF
-

-
If a table is in first normal form, then every cell contains one and only one atomic value. That is, no arrays of values, and no NULL entries. First normal form also requires every row be distinct.
-
First normal form can be described as making sure the tables are not sparse. We require that there be no NULL pointers and that there be no arrays of data in each element of data. This can be performed as a process of moving the repeats and all the optional content to other tables. Anywhere there is a NULL, it implies optional content.
-
DoD Book:
-
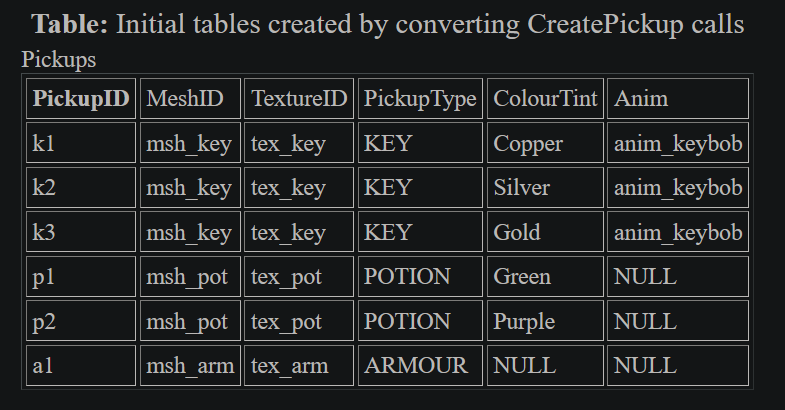
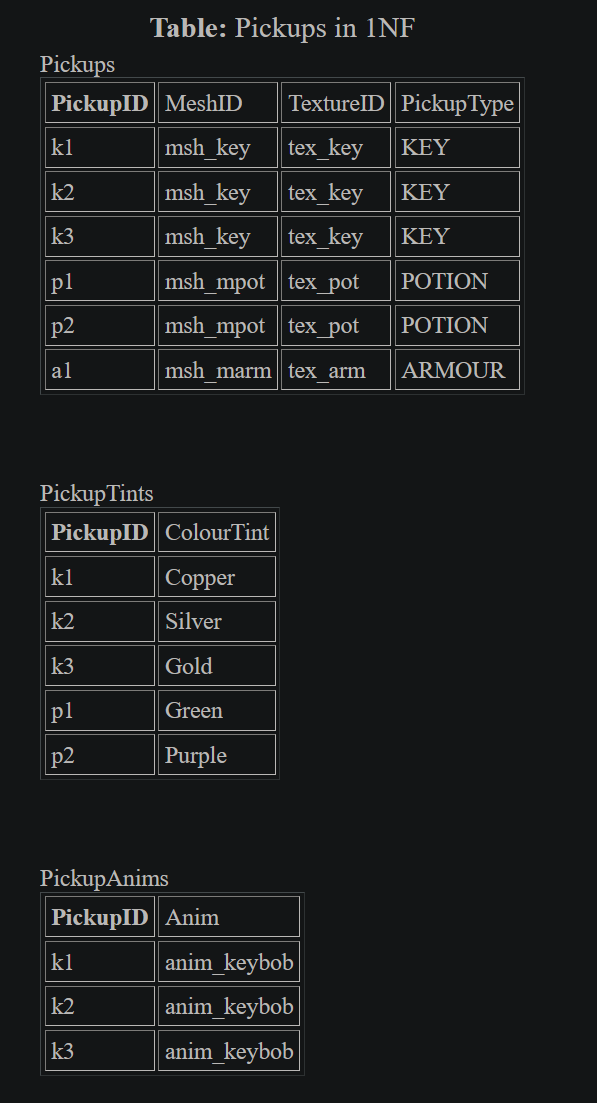
For the Pickups Table:
-
-
Two things become evident at this point, firstly that normalization appears to create more tables and fewer columns in each table, secondly that there are only rows for things which matter. The former is worrisome, as it means more memory usage. The latter is interesting as when using an object-oriented approach, we allow objects to optionally have attributes. Optional attributes cause us to check they are not NULL before continuing. If we store data like this, then we know everything is not NULL. Moving away from having to do a null check at all will make your code more concise, and you have less state to consider when trying to reason about your systems.
-
-
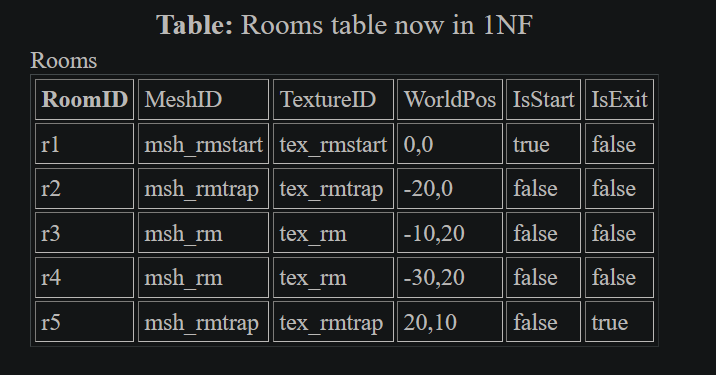
For the Rooms Table:
-
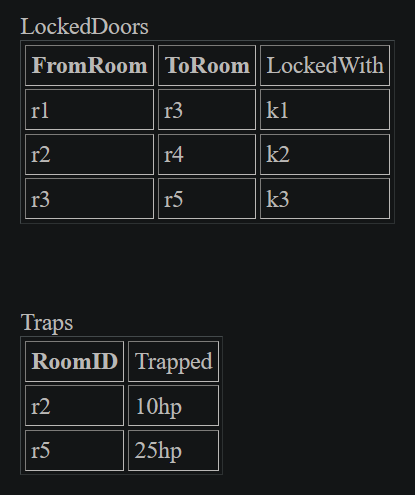
In there we saw single elements that contained multiple atomic values. We need to remove all elements from this table that do not conform to the rules of first normal form. First, we remove reference to the pickups, as they had various quantities of elements, from none to many. Then we must consider the traps, as even though there was only ever one trap, there wasn't always a trap. Finally, we must strip out the doors, as even though every room has a door, they often had more than one. Remember that the rule is one and only one entry in every meeting of row and column. In table [*] it shows how we only keep columns that are in a one to one relationship with the RoomID.
-
-
Now we will make new tables for Pickups, Doors, and Traps.
-
 .
.
-
 .
.
-
If you look at the Doors table, you can immediately tell that neither column is a candidate for the primary key, as neither contain only unique values. What is unique though is the combination of values, so the primary key is made up of both columns. In the table LockedDoors, FromRoom and ToRoom are being used as a lookup into the Doors table. This is often called a foreign key, meaning that there exists a table for which these columns directly map to that table's primary key.
-
In this case, the primary key is made up of two columns, so the LockedDoors table has a large foreign key and a small bit of extra detail about that entry in the foreign table.
-
-
Laying out the data in this way takes less space in larger projects as the number of NULL entries or arrays would have only increased with increased complexity of the level file. By laying out the data this way, we can add new features without having to revisit the original objects. For example, if we wanted to add monsters, normally we would not only have to add a new object for the monsters, but also add them to the room objects. In this format, all we need to do is add a new table such as the table below.
-
 .
.
-
And now we have information about the monster and what room it starts in without touching any of the original level data.
-
Many elements
-
They’re all valid in different contexts.
-
Repeated rows (relational / normalized) — baseline
InventoryItems ------------------------- | inventory_id | item | ------------------------- | 0 | sword | | 0 | ammo | | 0 | fruit |-
For ECS:
-
Queries like query(Sprite) become ambiguous: do you draw one sprite or many? Extra logic required.
-
Cache locality degrades: the dense array now contains vectors/allocations per entity.
-
Systems that want only the main sprite must scan/branch inside the array for each entity.
-
-
-
Single row with an array (grouped, still structured)
Inventories ------------------------------ | inventory_id | items | ------------------------------ | 0 | [sword, ammo, fruit] -
Single row with a map / dictionary (counts included):
Inventories ---------------------------------------- | inventory_id | items | ---------------------------------------- | 0 | { sword:1, ammo:50, fruit:3 }
2NF
-
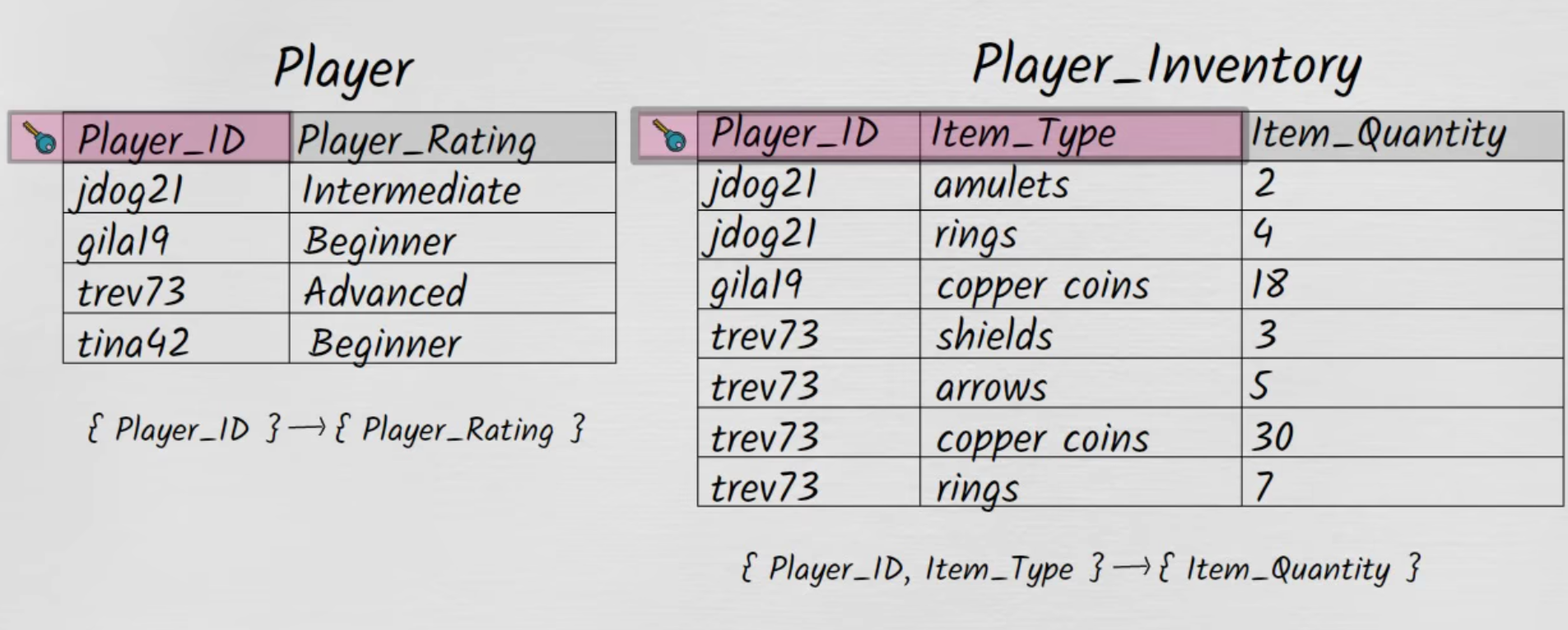
Problem :
-
 .
.
-
Deletion Anomaly :
-
If
gila19loses its only item, all information for this player is lost.
-
-
Update Anomaly :
-
If
jdog21updates itsPlayer_RatingtoAdvanced, but this is not updated across all of his entries, the data will be inconsistent.
-
-
Insertion Anomaly :
-
If a new player joins the game, but doesn't have any items yet, it cannot be inserted in the table.
-
-
-
Fixing with 2NF :
-
 .
.
-
-
DoD Book:
-
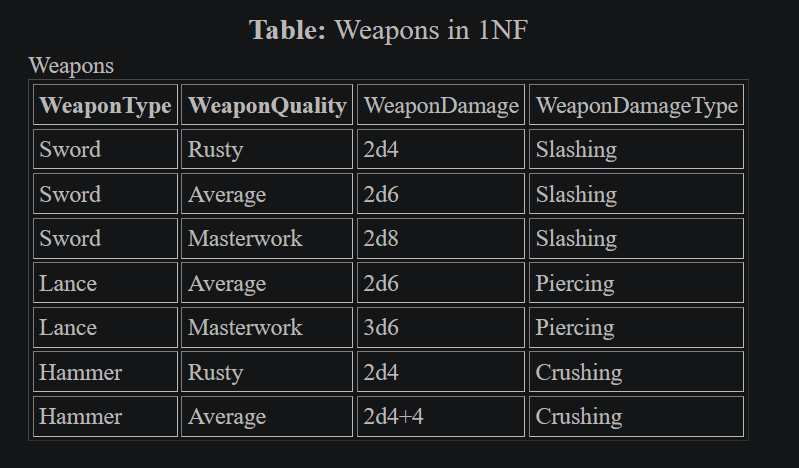
Second normal form is about trying to pull out columns that don't depend on only a part of the primary key. This can be caused by having a table that requires a compound primary key, and some attributes of the row only being dependent on part of that compound key. An example might be where you have weapons defined by quality and type, and the table looks like that in table [*], what you can see is that the primary key must be compound, as there are no columns with unique values here.
-
-
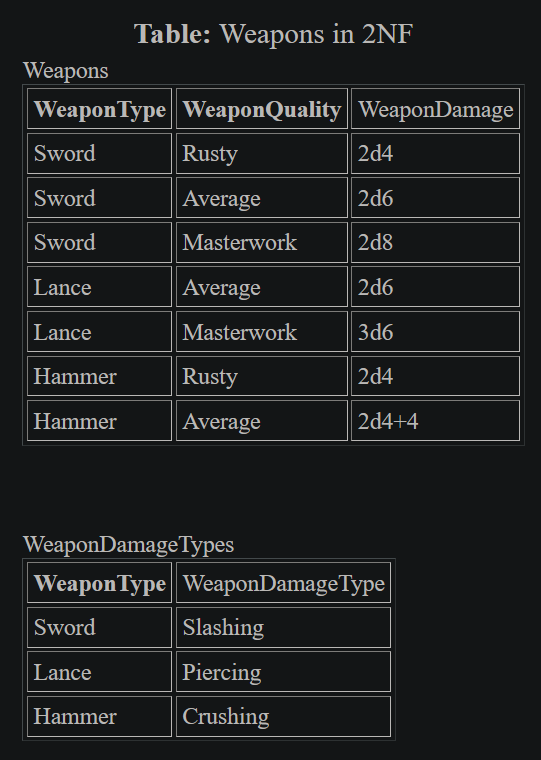
It makes sense for us looking at the table that the primary key should be the compound of WeaponType and WeaponQuality, as it's a fairly obvious move for us to want to look up damage amount and damage type values based on what weapon we're using. It's also possible to notice that the DamageType does not depend on the WeaponQuality, and in fact only depends on the WeaponType. That's what we mean about depending on part of the key. Even though each weapon is defined in 1NF, the type of damage being dealt currently relies on too little of the primary key to allow this table to remain in 2NF. We split the table out in table [*] to remove the column that only relies on WeaponType. If we found a weapon that changed DamageType based on quality, then we would put the table back the way it was. An example might be the badly damaged morningstar, which no longer does piercing damage, but only bludgeons.
-
-
3NF / Boyce-Codd Normal Form (BCNF)
-
Problem :
-
 .
.
-
The
Player_Ratingdepends onPlayer_Skill_Level.
-
-
Fixing with 3NF :
-
 .
.
-
-
DoD Book:
-
When considering further normalization, we first have to remove any transitive dependencies. By this we mean any dependencies on the primary key only via another column in the row.
-
Assets:
-
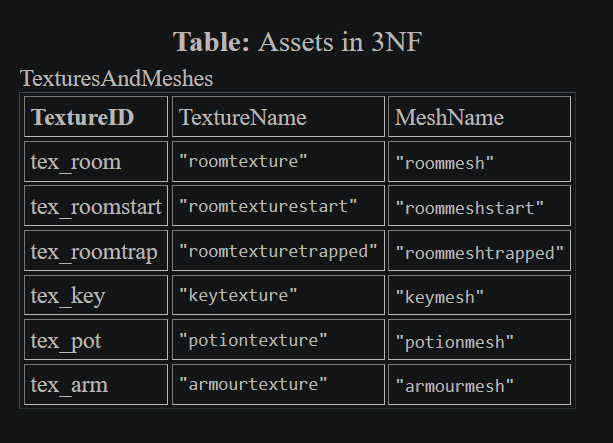 .
.
-
-
Rooms:
-
-
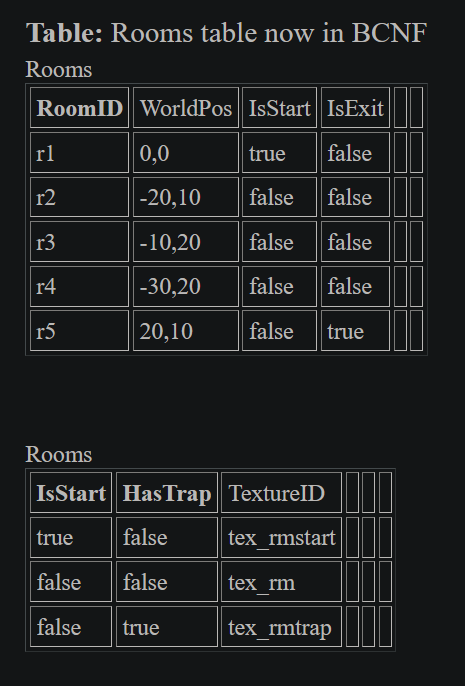
4NF
-
Problem :
-
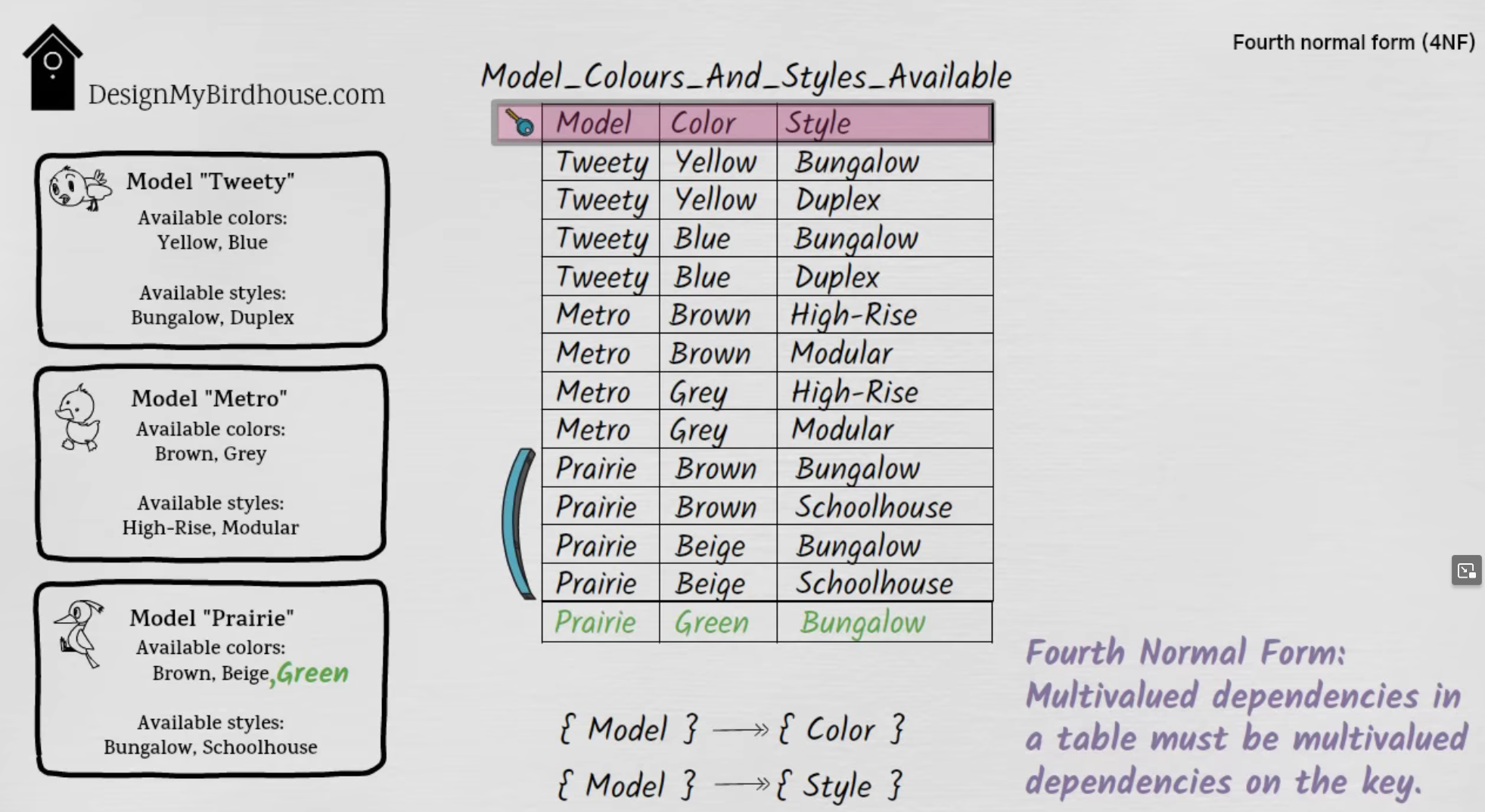 .
.
-
Available
Colors should be totally independent fromStyles, but when adding a newColor, this table requires having to add 2 entries: one forSchoolhouseandBungalow.
-
-
Fixing with 4NF :
-
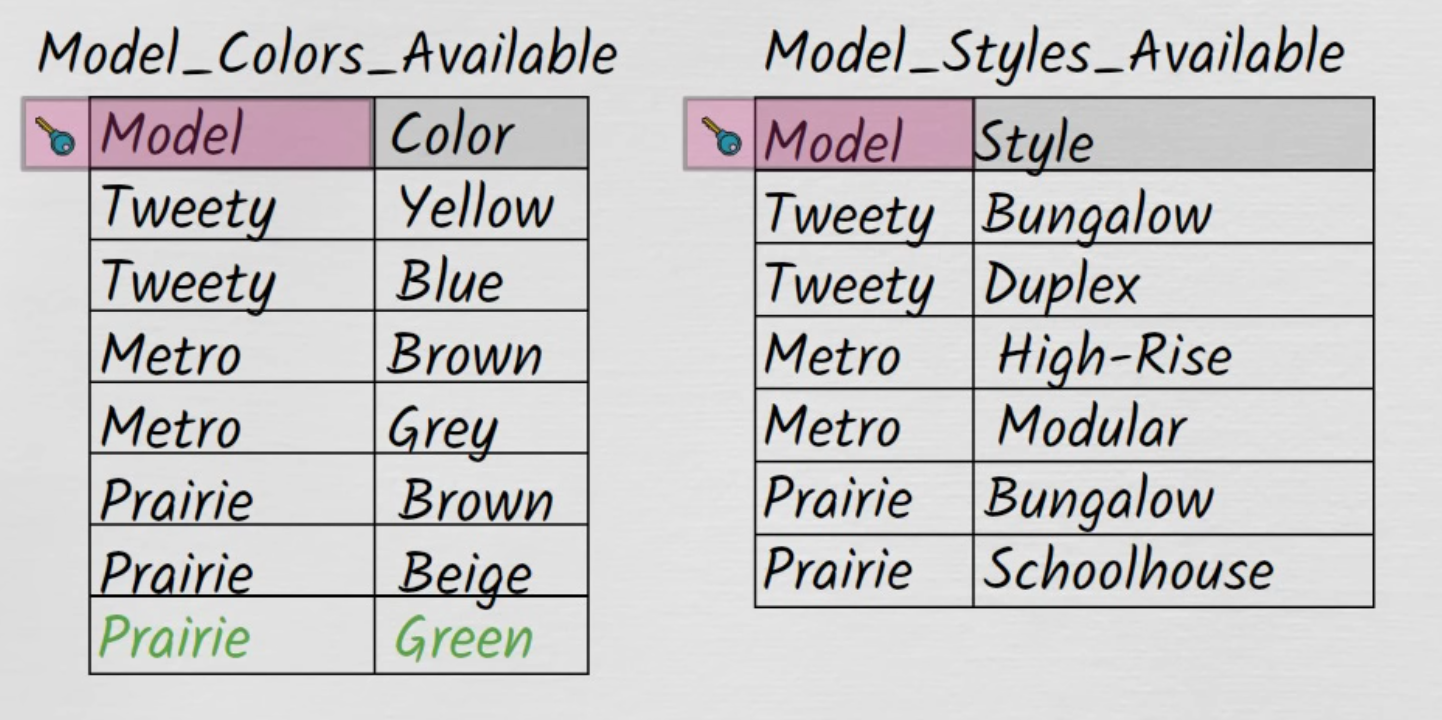 .
.
-
5NF
-
Problem :
-
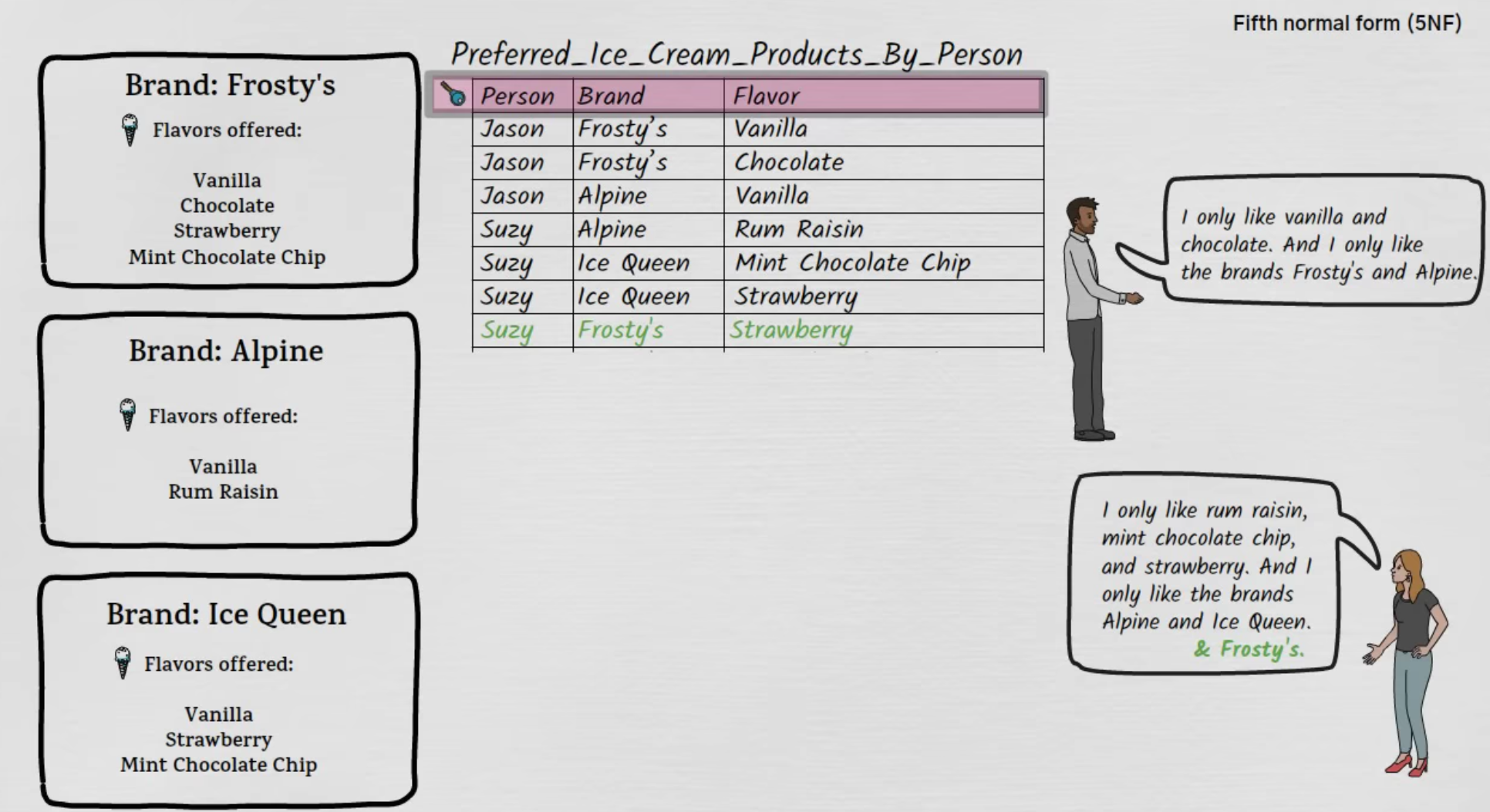 .
.
-
If
Suzydecides that she likes theBrandFrosty'sas well, and we forget to add the entrySuzy, Frosty's, Mint Chocolate Chip, then this is a logical inconsistency.
-
-
Fixing with 5NF :
-
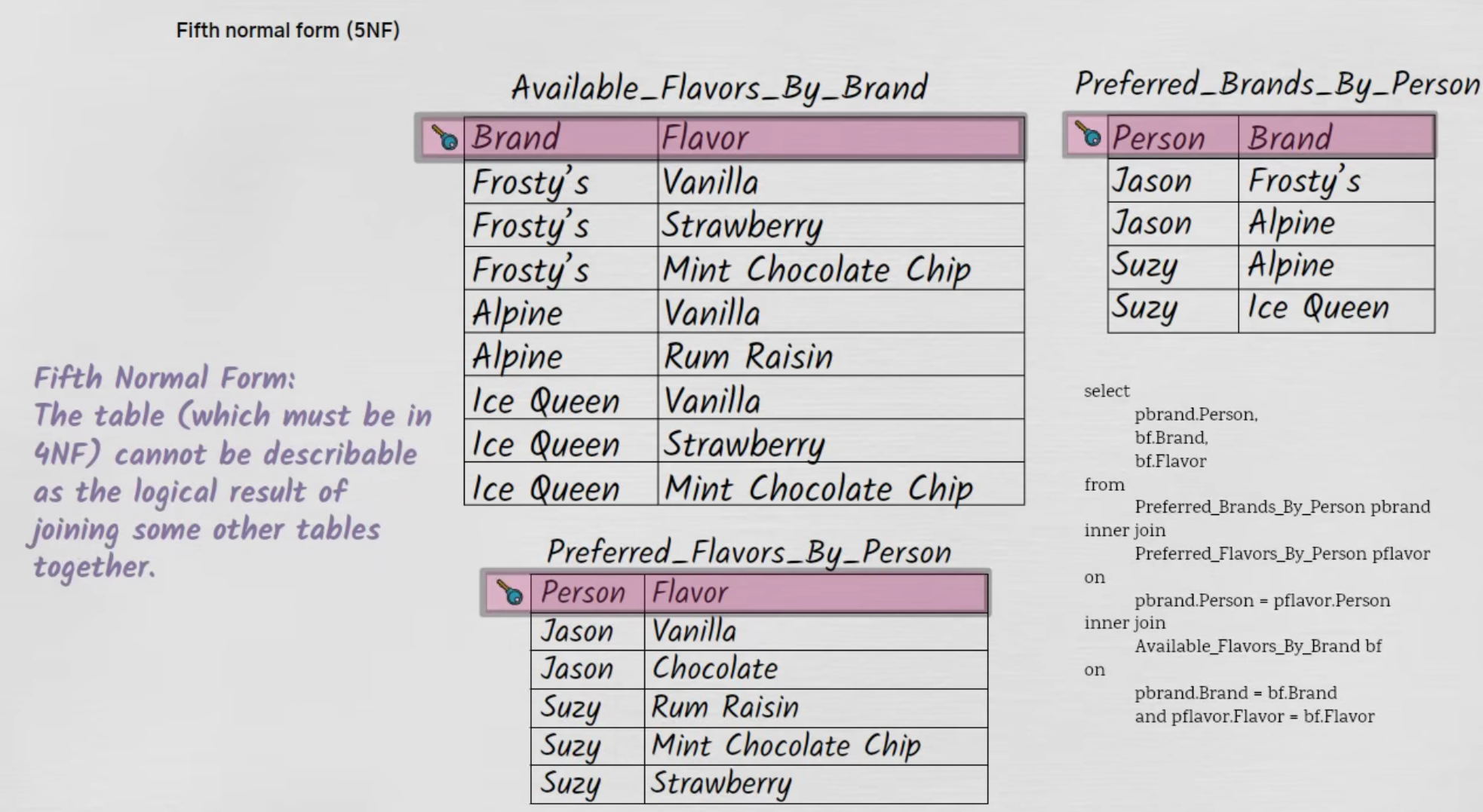 .
.
-
Domain Key Normal Form
-
Domain key normal form is normally thought of as the last normal form, but for developing efficient data structures, it's one of the things best studied early and often. The term domain knowledge is preferable when writing code as it makes more immediate sense and encourages use outside of keys and tables. Domain knowledge is the idea that data depends on other data, but only given information about the domain in which it resides. Domain knowledge can be as simple as awareness of a colloquialism for something, such as knowing that a certain number of degrees Celsius or Fahrenheit is hot, or whether some SI unit relates to a man-made concept such as 100m/s being rather quick.
-
An example of where domain knowledge can help with catching issues can be with putting human interpretations of values into asserts. Consider an assert for catching physics systems blowups. What is a valid expected range of values for acceleration? Multiply it by ten, and you have a check for when everything goes a bit crazy.
-
Some applications avoid the traditional inaccurate and erratic countdown timer, and resort to human-readable forms such as in a few minutes or time to grab a coffee, however domain knowledge isn't just about presenting a human interpretation of data. For example things such as the speed of sound, of light, speed limits and average speed of traffic on a given road network, psychoacoustic properties, the boiling point of water, and how long it takes a human to react to any given visual input. All these facts may be useful in some way, but can only be put into an application if the programmer adds it specifically as procedural domain knowledge or as an attribute of a specific instance.
-
Domain knowledge is what leads to inventions such as JPEG and MP3. Thinking about what is possible, what is possible to perceive, and what can possibly be affected by user actions, can reduce the amount of work done by an application, and can reduce its complexity. When you jump in a game with physics, we don't move the world down by fractions of a nanometer to represent the opposite reaction caused by the forces applied.